domain modeling made functional
domain-driven design
why software projects really fail
although most think that software fails because of bad code, the reality is actually because of bad understanding.
think of software development as a pipeline. requirements go in one end, working software comes out the other. if you put garbage in, no amount of good code will save you. the garbage can mean unclear requirements, wrong assumptions, or misaligned mental models.

the deeper problem is the developer's understanding that ships to production, not the domain expert's. and in traditional processes, those two understandings drift further and further apart.
agile development improved this by creating a feedback loop, developers deliver something then domain experts review it, so that misunderstandings get corrected. but even agile has a problem: the developer is still translating. they are converting the domain expert's mental model into code. translation always loses something.
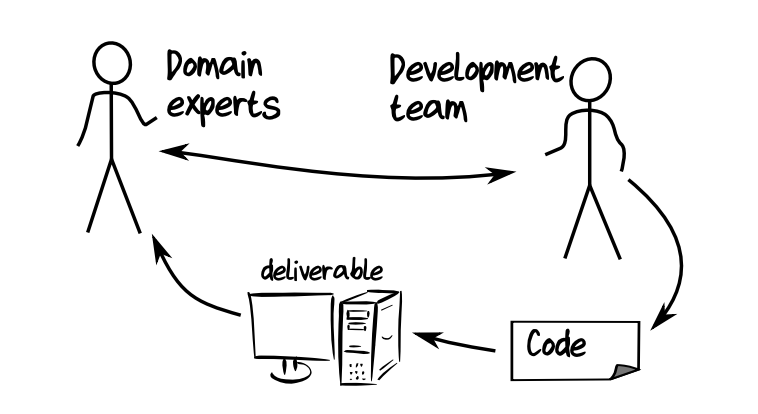 DDD proposes a third way as solution.
DDD proposes a third way as solution.
the core idea: one shared model
to avoid translating and losing something in between, domain experts and developers should shares a shared model that directly reflects how the business thinks.
that is domain-driven-design in one sentence.
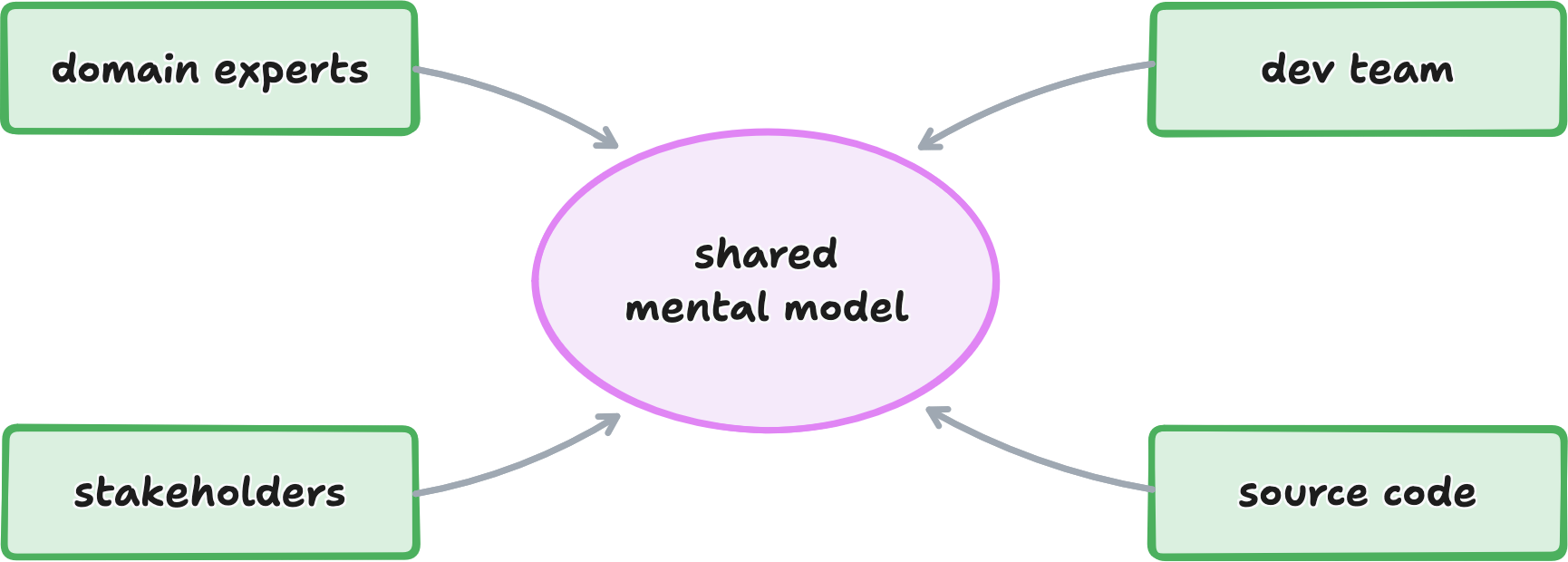
everyone uses the same concepts, names, and language.
when this works, the benefits are concrete:
- faster delivery (less back-and-forth),
- more accurate solutions (the code is what the business model needs),
- less rework (everyone's aligned from the start),
- easier maintenance (new developers can read he code and understand the business logic directly)
DDD achieves this shared model through four practices.
practice 1: start with events, not data
a business is not a database. it is a series of things that happen.
when you first look at business domain, the temptation is to ask "what data do we store?". but that is looking at a snapshot. the real value is the flow:
- what causes things to change
- what happens as a result
- how one action triggers the next
DDD calls these significant moments Domain Events, things that happened in the business that matter. they are always written in the past tense because they are facts: "Order placed," "Payment received," "Customer registered."
why past tense? because an event is a record of something that already occurred. it can't be undone. it is not a suggestion or a request, it happened.
to discover these events, DDD uses a technique called Event Storming: you gather everyone in a room (domain experts, developers, testers, anyone with questions or answers), cover the walls in paper, and have people post sticky notes with events. in this session, people from different departments discover how their work connects and where the gaps are.
from an event storming session on an order-taking system for a small manufacturer, you might surface events like: order form received → order placed → order shipped → customer notified → shipment signed for. each one is a real thing happened, written in the past tense.
practice 2: connect events to commands and workflows.
events don't happen by magic. something causes them.
in DDD, a command is a request for something to happen such as "Place this order," "Ship this package." commands are written in the imperative. a command triggers a workflow (the actual process), and if the workflow succeeds, it produces one or more events.
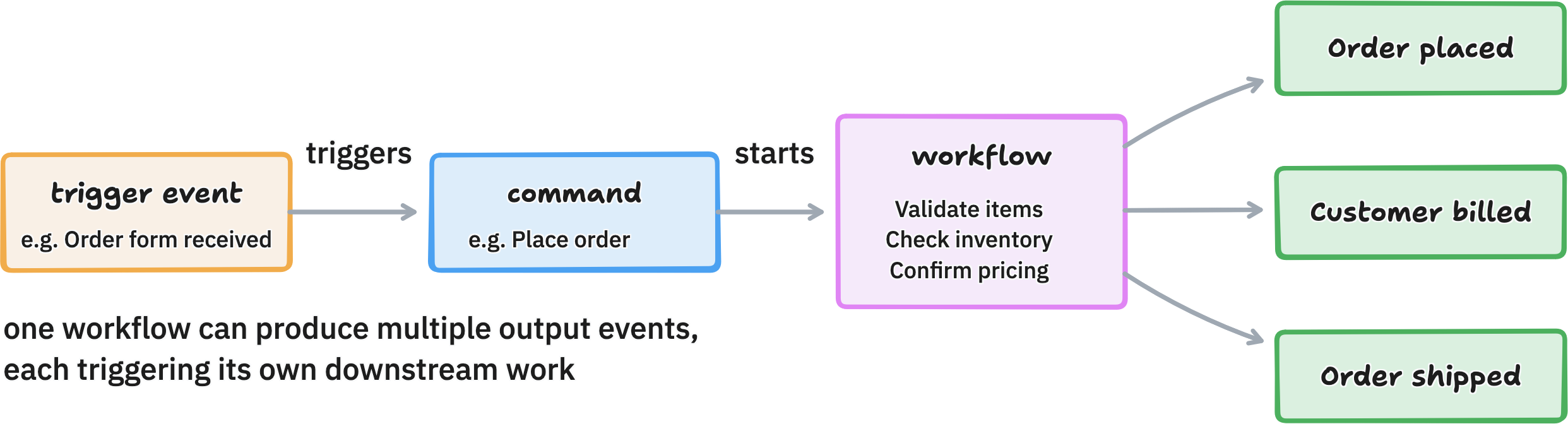
the pipeline pattern: event → command → workflow → events. it maps cleanly how functional programming works (inputs in, outputs out, no hidden state). it also makes the system's behavior easy to reason about and test.
notice that output events become inputs for other workflows. the "Order placed" event triggers both the shipping team's workflow and the billing team's workflow. events are how different parts of the business communicate.
practice 3: break the domain into subdomains
large problems are hard, but smaller problem are manageable. find the natural seams and cut there.
a domain in DDD is simply the area of knowledge a domain expert is expert in. "Billing" is what the billing department knows. "Shipping" is what the shipping team knows. you don't need a precise dictionary definition, you just need to know who to ask.
within a domain, you may find subdomains. they are smaller, distinct areas of specialization. web programming is a subdomain of general programming. CSS is a subdomain of web programming. the key insight: the business already knows where these seams are. look at the org chart. different departments = different domains.
for an order-taking system, the domains might be: order-taking, shipping, and billing. they overlap slightly (a shipper needs to know a little about billing: an order-taker needs to know a little about shipping), but each has a clear core of expertise.
not all domains matter equally. DDD distinguish three types:
- core domains (your competitive advantage, invest heavily here)
- supportive domains (needed but not unique, build carefully)
- generic domains (commodity functionality, consider buying off the shelf
practice 4: build a bounded context for each subdomain
real-world domains have fuzzy boundaries. software needs crisp ones.
in the problem space (the real world), domains overlap and blur. in the solution space (your code), you need clean interfaces. the DDD term for a software component with clear, deliberate boundaries is a bounded context.
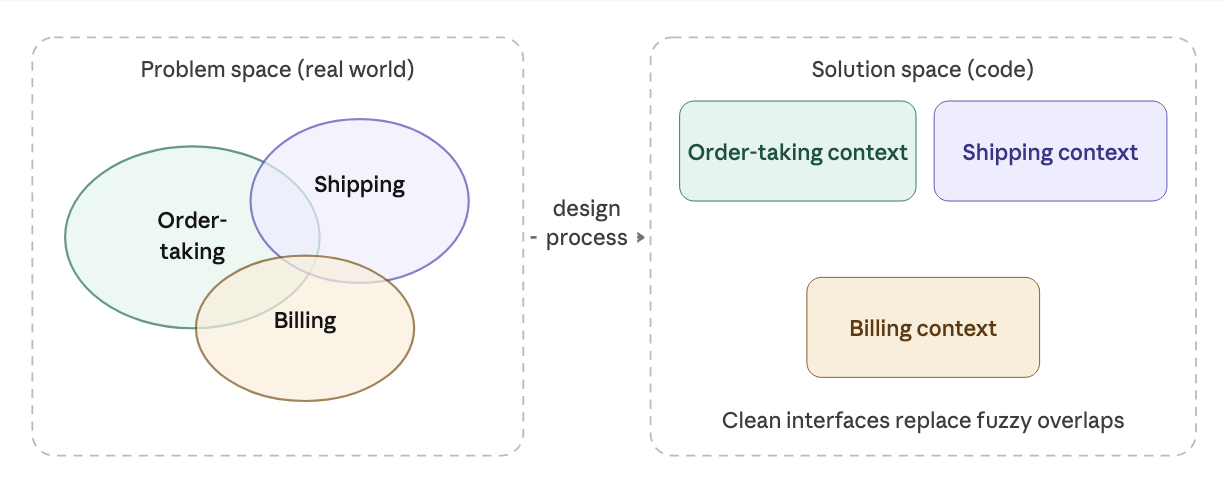
why context? each bounded context has its own specialized knowledge and its own internal language. "order" in the shipping context means something slightly different than "order" in the billing context, one cares about quantities and addresses, the other about prices and invoicing. each context gets its own model.
why bounded? because we deliberately limit what each subsystem knows about the others. they talks to each other through explicit interfaces (APIs, events). this loose coupling means they can change independently. a billing system upgrade doesn't break the shipping system.
getting the boundaries right is one of the hardest parts of DDD. some heuristics that help:
- listen for shared language (if two teams use the same words to mean the same things, they might be in the same context)
- watch for teams that can't work independently (they may be over-coupled)
- beware scope creep (boundaries that grow too large stop working as boundaries)
practice 5: create a context map
once you have separate subsystems, you need to understand how they connect.
a context map is a high-level diagram showing your bounded contexts and the flows between them. it is not an architectural diagram with every endpoint and data schema. it is a route map: just the main paths, so you can reason about the big picture.
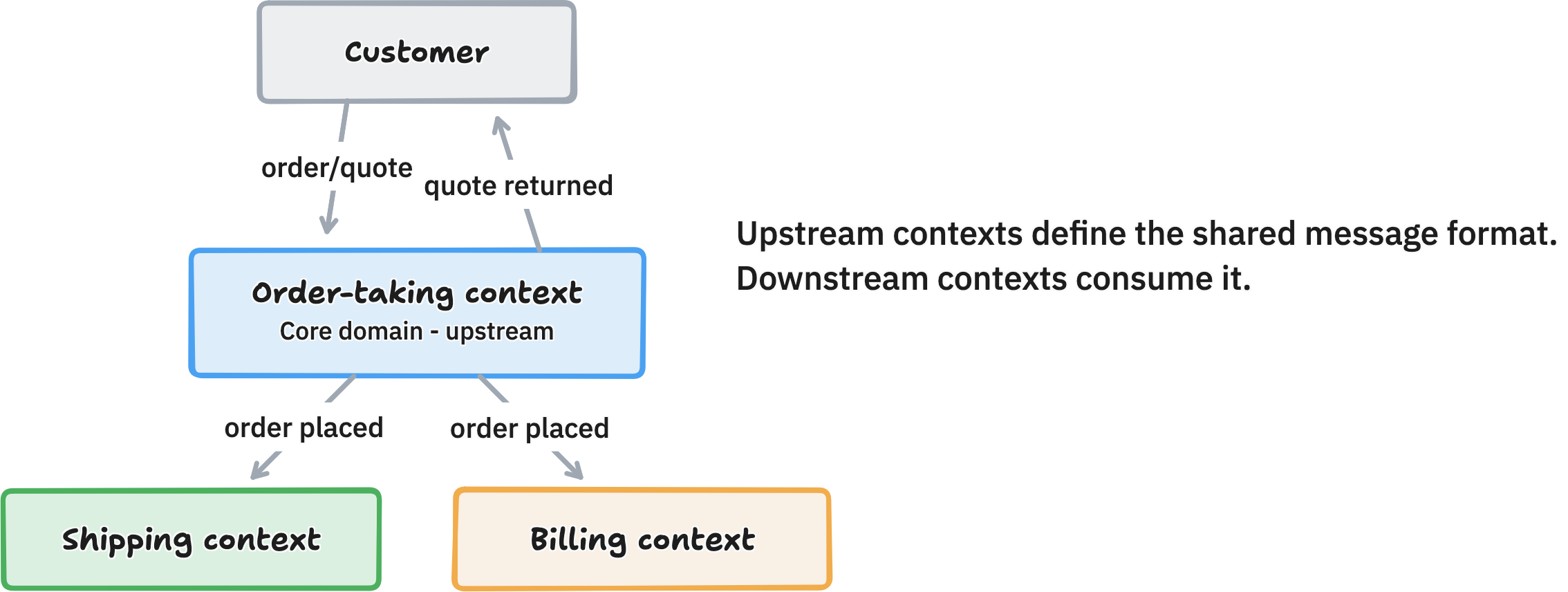
in this map, the order-taking context is upstream, it defines the format of the "order placed" event. shipping and billing are downstream, they consume it. the upstream context generally has more say over the shared format, but when integrating with legacy systems, the downstream may be inflexible and force the upstream to adapt (or you need a translation layer in between).
practice 6: build a ubiquitous language
if two people use the same word to mean different things, they will misunderstand each other, no matter how clearly they speak.
the ubiquitous language is the shared vocabulary of a bounded context. every concept that matters gets a name agreed on by the whole team (developers and domain experts), and that name is used everywhere: in conversations, in requirements, and in the code itself.
so if a domain expert calls something an "Order," your code has a class called Order. if they call an action "Placing an order," your code has a function called placeOrder. no inventing technical names like OrderManager, OrderHelper, or OrderProcessor that the business wouldn't recognize.
a few practical notes on the ubiquitous language:
it's not dictated — it's built collaboratively. domain experts and developers negotiate it together. it evolves as the team learns more about the domain.
it's context-specific. "Order" means something different in shipping than in billing. don't force one universal meaning. let each bounded context have its own dialect.
it should be written down, a living document or wiki page that tracks terms and definitions. this helps new team members onboard quickly and keeps everyone aligned as the project evolves.
understanding the domain
before writing a single line of code, you need to deeply understand the problem you are solving.
what is a domain?
a domain is simply the area of business your software is meant to solve. it is everything the business does, knows, and cares about.
the core idea behind Domain-Driven Design is this: let the business problem shape your software design, not the other way around. don't make the business fit your database schema or your class hierarchy.
to do this well, you need to talk to domain experts, the people who actually do the work. in this chapter, we interview ollie from the order-taking department to understand how orders are processed.
the interview: listen first, design later
the goal of the first interview is simple: understand the inputs and outputs of the workflow.
You: "What information do you need to start the order-placing process?" Ollie: "It all starts with an order form that customers fill out and send us." You: "So customers browse product pages, add items to a cart, and check out?" Ollie: "No, of course not. Our customers already know exactly what they want. They might order 200–300 items at once — clicking through product pages would be terribly slow. We just need a simple form where they type in product codes and quantities."
an important lesson here is the developer assumed a standard e-commerce shopping cart and it is completely wrong. the real users are bulk-ordering experts who need speed and efficiency, not browsing. good requirements gathering means listening like an anthropologist. bring zero assumptions.
continuing the interview, we learn the scale of the system:
Ollie: "We're B2B. About 1,000 business customers, each ordering roughly once a week. Around 200 orders per business day, consistent all year."
this tells us three important things about what we are actually building:
- scale is modest. ~200 orders/day means we don't need to architect for millions of requests.
- users are experts. don't put friction in their way, they know what they want.
- reliability over speed. "customers want to know we'll respond predictably." consistency and an audit trail matter more than milliseconds.
mapping the workflow: inputs, outputs, side effects
continuing the interview, we learn the full sequence of what happens when an order arrives:
- check that product codes are real (look them up in the product catalog)
- calculate the cost of each line item and total it up
- send copies to the shipping and billing departments
- email an acknowledgment back to customer
we also discover something important: there is difference between an order and a quote. a quote just calculates prices, nothing gets dispatched. the same form is used for both, but the workflow are completely different.
this gives us a clean picture of the workflow:
Input: Order form
Other input: Product catalog
Workflow: Place Order
Output event: "OrderPlaced" (notifies Shipping & Billing)
Side effect: Order acknowledgment emailed to customer
a critical insight here: the output of a workflow is always the event it generates, the things that kick off actions in other parts of the system. the acknowledgement email is a side effect, not the output. the real output is the OrderPlaced event that tells other departments to act.
two design traps to avoid
at this point, most developers feel the urge to start designing the implementation. that instinct leads to two classic mistakes.
- trap 1 - database-first thinking
you look at the order form and think immediately: Order table, OrderLine table, Customer table, foreign keys... this forces the domain to fit relational storage rules, and you lose important distinctions. for example, an Order requires a billing address; a Quote does not. a shared foreign key can't express that cleanly. the design gets distorted to fit the database.
- trap 2 - class-hierarchy thinking
you start creating an OrderBase abstract class with Order and Quote as subclasses. but OrderBase doesn't exist in the real world, it is a programming artifact with no meaning to Ollie. ask the domain expert what an OrderBase is and watch the confused look on their face.
the right approach is to model what the domain expert actually talks about, in their language, capturing the real distinctions that matter to the business. this principle is called persistence ignorance, your domain model should be designed completely independent of how the data will be stored. let the database and class structure follow from the domain model, not the other way around.
documenting the domain in plain language
instead of UML diagrams or class hierarchies, we use a simple pseudo-language. it's readable by non-programmers, so you can share it with domain experts and work on it together. AND means both parts are required. OR means either one will do.
workflow "Place Order"
triggered by: "Order form received" event
primary input: An order form
other input: Product catalog
output events: "Order Placed" event
side-effects: An acknowledgment is sent to the customer
data Order =
CustomerInfo
AND ShippingAddress
AND BillingAddress
AND list of OrderLines
AND AmountToBill
data OrderLine =
Product
AND Quantity
AND Price
what validation really means
when we ask Ollie to walk through processing an order in detail, new complexity emerges.
Ollie: "First I check the customer name, email, and addresses — using a special address-checking application." Ollie: "Then I check the product codes. Widget codes start with 'W' then four digits. Gizmo codes start with 'G' then three digits. And I verify each one actually exists in the product catalog." Ollie: "Then the quantities. Widgets are sold by the unit — whole numbers only. Gizmos are sold by the kilogram. Max 1,000 units for widgets. For gizmos, between 0.05 kg and 100 kg."
this reveals that product code validation has two distinct levels:
- syntax check - does the code match the right format? you can check this from the code alone, no catalog needed.
- existence check - does the product actually exist in the catalog? this requires a lookup.
and note that Ollie mentioned a third-party address checking service we missed entirely during the initial high-level discovery. this is a new dependency we need to account for.
we can now model the constrained types properly:
data WidgetCode = string starting with "W" then 4 digits
data GizmoCode = string starting with "G" then 3 digits
data ProductCode = WidgetCode OR GizmoCode
data UnitQuantity = integer between 1 and 1000
data KiloQuantity = decimal between 0.05 and 100.00
data OrderQuantity = UnitQuantity OR KiloQuantity
why bother capturing these constraints in the model? because constraints make bugs impossible. if UnitQuantity can only ever be 1-1000, you can never accidentally end up with negative order or a billion-unit shipment. the model prevents the error before any code runs.
the order lifecycle: orders change over time
one of the most important discoveries from the interview is that an order isn't a single static thing, it moves through distinct states. Ollie literally puts physical marks on paper forms to tell them apart. we need to do the same in our model.
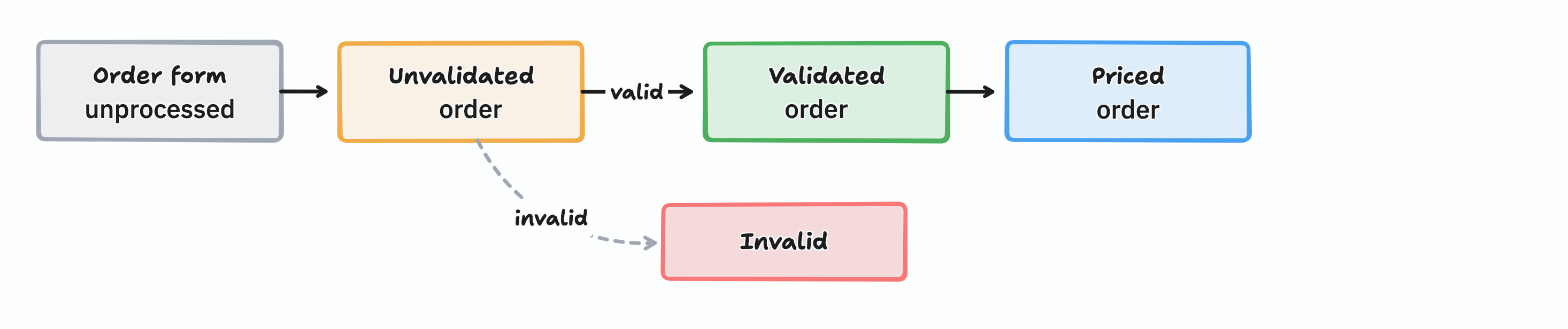
Unvalidated → Validated → Priced → Acknowledged
each state has different data and different rules. we capture this by giving each state its own type:
// Straight off the mail pile — nothing is verified yet
data UnvalidatedOrder =
UnvalidatedCustomerInfo
AND UnvalidatedShippingAddress
AND UnvalidatedBillingAddress
AND list of UnvalidatedOrderLines
// After address and product code checks pass
data ValidatedOrder =
ValidatedCustomerInfo
AND ValidatedShippingAddress
AND ValidatedBillingAddress
AND list of ValidatedOrderLines
// After prices have been calculated
data PricedOrder =
ValidatedCustomerInfo
AND ValidatedShippingAddress
AND ValidatedBillingAddress
AND list of PricedOrderLines // each line now has a price
AND AmountToBill // sum of all line prices
why does this matter? it each state is a distinct type, it becomes impossible to accidentally send an unpriced order to the shipping department, the type system won't allow it. business rules get encoded directly into the model, so entire classes of bugs simply can't exist.
the full workflow, written out
now we can document the complete workflow, including what happens when things go wrong:
workflow "Place Order" =
input: OrderForm
output: OrderPlaced event OR InvalidOrder
// Step 1
do ValidateOrder
if invalid → add to InvalidOrder pile; stop
// Step 2
do PriceOrder
// Step 3
do SendAcknowledgmentToCustomer
return OrderPlaced event
substep "ValidateOrder" =
input: UnvalidatedOrder
output: ValidatedOrder OR ValidationError
dependencies: CheckProductCodeExists, CheckAddressExists
validate customer name
check shipping and billing addresses exist
for each line: check product code format; check code exists in catalog
if all OK: return ValidatedOrder
else: return ValidationError
substep "PriceOrder" =
input: ValidatedOrder
output: PricedOrder
dependencies: GetProductPrice
for each line: get price from catalog; set line price
set AmountToBill = sum of all line prices
substep "SendAcknowledgmentToCustomer" =
input: PricedOrder
output: none
create and email acknowledgment letter + order to customer
Summary
six things to take away from this chapter:
- listen before you design. your assumptions are often wrong. let the domain expert correct you early, not your users in production.
- don't design around a database. persistence is an implementation detail. design the domain first; figure out storage later.
- son't design around class hierarchies. abstractions like
OrderBasedon't exist in the real world. use the language the domain expert uses. - capture states explicitly.
UnvalidatedOrder,ValidatedOrder, andPricedOrderare meaningfully different things. name them differently. - capture constraints early.
UnitQuantityis 1–1,000.KilogramQuantityis 0.05–100. these bounds prevent a whole class of bugs before a single line of code is written. - complexity is a good discovery. the domain model got much more complicated as we learned more, that's exactly right. better to find complexity in the design phase than while debugging production.
"a few weeks of programming can save you hours of planning." the inverse is also true: a few hours of careful domain modeling can save you weeks of building the wrong thing.
a functional architecture
how to translate a domain model into software, using bounded context, events, trust boundaries, and the Onion Architecture.
start simple: why architecture can wait
at the start of a project, you don't fully understand the domain yet. the smartest move you can do at this stage is to reduce the unknown by talking to domain experts, run Event Storming sessions, gather requirements.
that said, you still need some architectural skeleton early on so you can start building before everything is understood.
walking skeleton is the minimum structure that demonstrate how the whole system hangs together. early feedback on a concrete implementation is the fastest way to discover gaps in your knowledge.
describing architecture: the c4 model
before anything else, we need shared vocabulary. we use Simon Brown C4 model with four zoom levels for describing a software system.

a good architecture defines clear boundaries between these levels, so that when requirements change, the cost of making changes stays low.
bounded context as autonomous islands
a bounded context is a self-contained subsystem with a well-defined boundary and its own vocabulary. think of it as a department in a company: shipping doesn't need to know how Billing works internally, it just needs the right information at the right time.
how big should a bounded context be?
there are three options, from simplest to most complex:
monolith all bounded contexts live inside one deployable unit, separated by code modules. easy to build, easy to refactor. start here.
service-oriented each bounded context is its own deployable service. useful once boundaries are well understood and teams are large.
microservices each individual workflow is its own deployable unit. only worthwhile when the operational cost is justified by clear benefits.
how context communicate: events
bounded contexts never call each other directly. instead, they communicate through events.
let's trace what happens when an order is placed:
- the
PlaceOrderworkflow in the order-taking context finishes and emits anOrderPlacedevent. - the event is placed on a queue (or published through another mechanism)
- the shipping context is listening for
OrderPlacedevents - when the event arrives, shipping creates a
ShipOrdercommand internally. - the
ShipOrderworkflow runs and, on success, emits anOrderShippedevent.

the event carries the data. an OrderPlaced event isn't just a ping, it includes all the data the downstream context needs to do its job. no follow-up queries required.
what travels across the boundary: DTOs
the objects inside a bounded context, called domain objects, are optimized for business logic. they carry rules and invariants: a quantity must be positive, a product code must exist in the catalogue.
the objects that travel between contexts are called Data Transfer Objects (DTOs). they are optimized for transport, flat, simple, easily serialized to JSON or XML. the OrderDTO inside an OrderPlaced event looks similar to the Order domain object but enforces none of its rules.
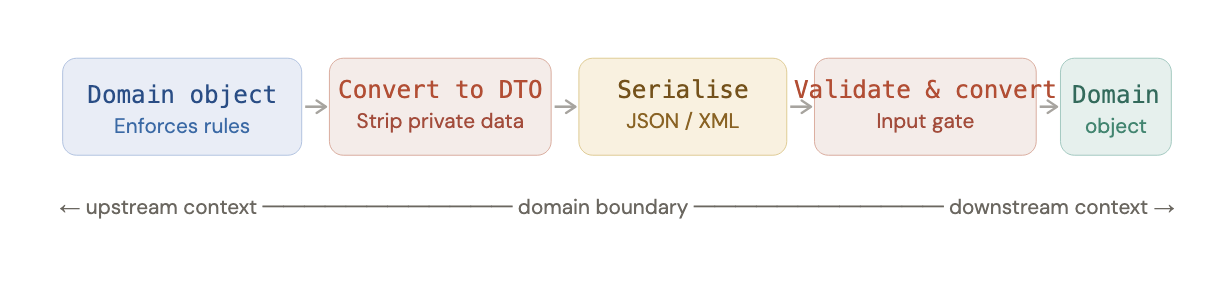
trust boundaries and validation gates
the perimeter of a bounded context is a trust boundary. inside: data is valid and trustworthy. outside: data is untrusted and could contain anything.
to enforce this, we place two gates at the edge of every workflow:
input gate validates everything coming in every incoming DTO is validated against domain constraints before the workflow sees it. if validation fails, the workflow is bypassed entirely and an error is returned. after the gate, the domain object is guaranteed to be valid.
output gate prevents private data leaking out converts domain objects to DTOs, deliberately dropping fields that downstream contexts don't need. for example, the billing context has no business knowing the shipping address, and the shipping context has no business knowing the credit card number.
the Anti-Corruption Layer (ACL) is an extended form of the input gate used when integrating with external systems whose vocabulary doesn't match your domain at all. rather than letting the external model corrupt your clean domain language, the ACL translates between the two, acting as a diplomatic interpreter so both sides can evolve independently.
relationship between contexts
any shared communication format creates some coupling, the events and DTOs form a contract between contexts. the DDD community has named three common patterns for how that contract is negotiated:
- shared kernel
- consumer-driven contract
- conformist
- anti-corruption layer
choosing the right relationship is often as much an organizational decision as a technical one, it reflects how the teams that own each context will collaborate.
workflows inside a bounded context
in functional architecture, each business workflow maps to a single function: it takes a command as input and returns a list of events as output.
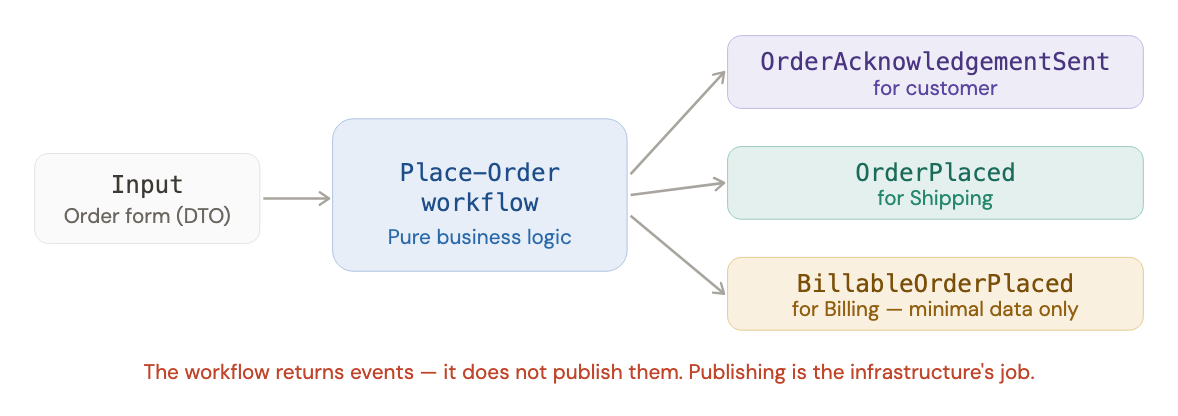
avoid internal event listeners in object-oriented designs, it's common to have a workflow raise an internal event and have separate handlers listen and react. this creates hidden dependencies, the execution chain is impossible to read from the code alone.
in functional design, instead of hidden listeners, you chain steps explicitly in a pipeline you can read from top to bottom: Place-Order → Acknowledge-Order → Create-BillableOrder. no global event manager, no mutable state, no surprise.
code structure: the onion architecture
the classic layered approach, API layer on top, database layer at the bottom, forces a single workflow change to ripple through every layer. it breaks the principle that code that changes together should live together.
the cleanest alternative is the Onion Architecture: place pure domain logic at the center, and let everything else surround it in outer rings. the single governing rule:
all dependencies must point inward. outer layers can depend on inner layers. inner layers must never know that outer layers exist.
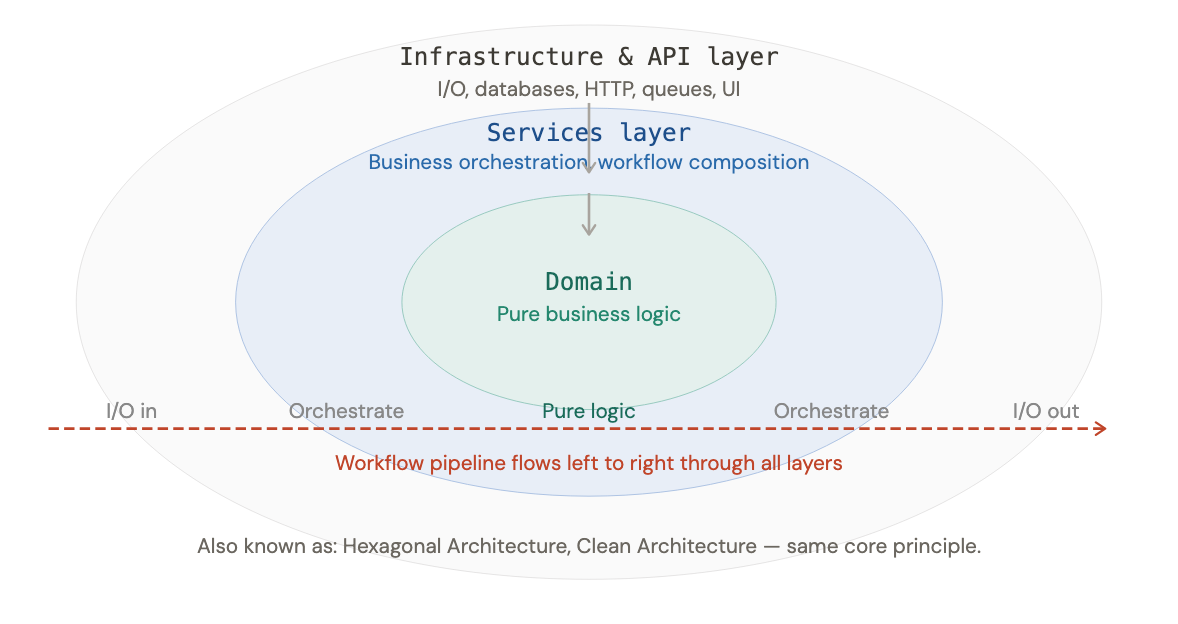
keep i/o at the edges
the most practical consequence of the Onion Architecture is this: database calls, file reads, network requests, all of it stays at the outermost layer.
a function that silently reaches into a database mid-workflow is impure, unpredictable, hard to test, impossible to reason about in isolation. so we structure every workflow in three phases:

i/o only at the start and end, the domain logic in the middle is pure, predictable, and easily testable.
this enforces persistence ignorance, the domain model has zero awareness of how or where data is stored. you can swap out your database without touching a line of business logic.
bonus effect: "you can't accidentally model your domain using a database if you can't access the database from inside the workflow." the constraint forces clarity.
glossary or terms introduced
| term | what it means |
|---|---|
| Domain object | an object that lives inside a bounded context and enforces business rules |
| DTO | a flat, serialisable object designed to travel between contexts |
| Shared Kernel | two contexts jointly own a shared design; changes require coordination |
| Consumer-Driven Contract | downstream context defines what it needs; upstream provides exactly that |
| Conformist | downstream context adapts to upstream's model as-is |
| Anti-Corruption Layer (ACL) | a translator between two different domain vocabularies |
| Persistence Ignorance | the domain model has zero knowledge of databases or storage details |
| Onion Architecture | domain at the centre; all dependencies point inward |
understanding types
convert those informal requirements into real, compilable code — using F#'s algebraic type system.
what is a function?
a function is a black box. something goes in, something comes out. it transform inputs into outputs.

in F#, you write a function like this:
let add1 x = x + 1 // takes a number, returns number + 1
F# infers the types for you.
reading type signature
every function has a type signature, a shorthand for what goes in and what comes out, using -> as the arrow.
let add1 x = x + 1 // int -> int
let add x y = x + y // int -> int -> int
read int -> int as: "takes an int, returns an int."
read int -> int -> int as: "takes two ints, returns an int." each parameter gets its own arrow.
when a function works with any type, f# uses a tick-prefix like 'a for generics:
let areEqual x y = (x = y) // 'a -> 'a -> bool
'a means "some type, as long as both x and y are the same type."
what is a type?
a type is just a name given to a set of possible values.
the type int16 is the label for every integer form -32768 to +32767. The type string is the label for every possible text value. the type Person is the label for every valid person record in your system. types have no built-in behavior, they are just named sets.

Jargon: values vs objects In functional programming, things are called values. Values are immutable data with no behavior. An OOP object bundles data and methods together and expects to be mutated. In F#, use "value."
building types from smaller types
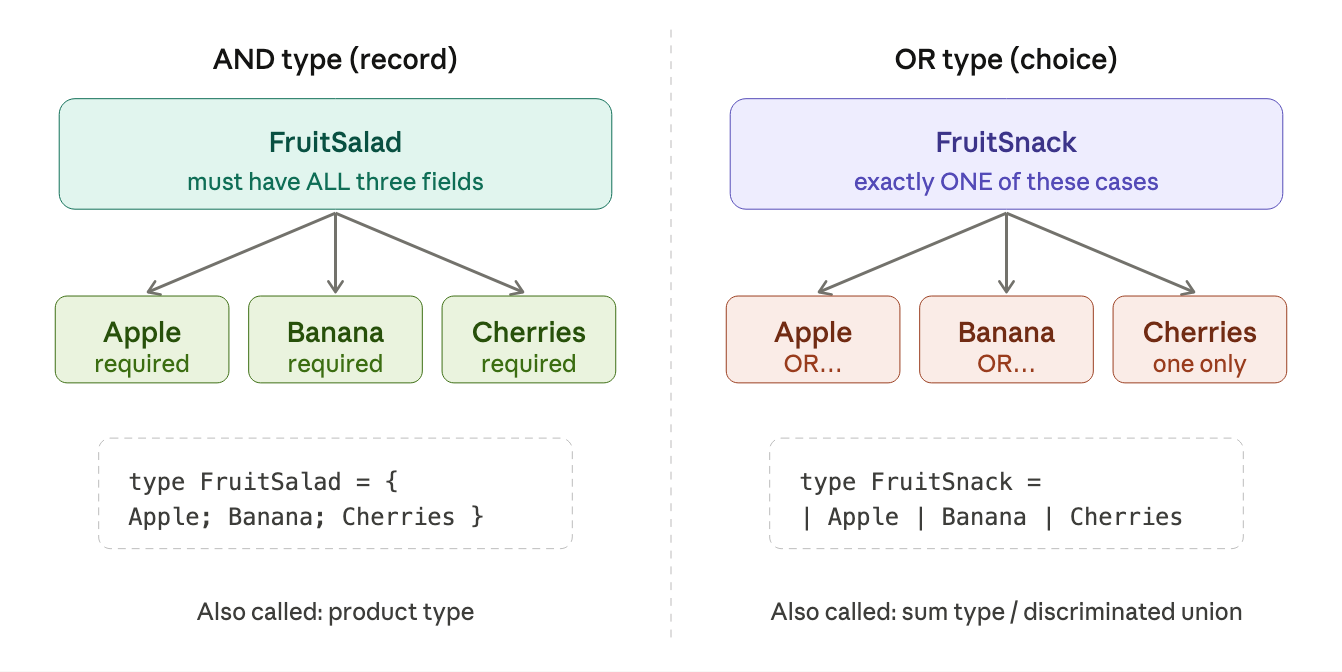
in F#, you combine smaller types into bigger ones in exactly two ways, AND and OR. this is called type composition, and it works like Lego bricks.
AND types - records
a record is an AND type. to make a FruitSalad, you need all the ingredients at once:
type FruitSalad = {
Apple : AppleVariety
Banana : BananaVariety
Cherries: CherryVariety
}
constructing one:
let mySalad = { Apple = Fuji; Banana = Cavendish; Cherries = Bing }
reading fields back with dot syntax:
let whichApple = mySalad.Apple // Fuji
OR types - discriminated unions
a discriminated union is an OR type. a FruitSnack is exactly one of the options:
type FruitSnack =
| Apple of AppleVariety
| Banana of BananaVariety
| Cherries of CherryVariety
each line (prefixed with |) is a case. the word before of is a tag. it distinguishes cases even if they carry the same underlying type.
constructing one:
let mySnack = Apple Fuji // tagged as an Apple case
let anotherSnack = Banana Cavendish
reading a value back requires pattern matching, F# forces you to handle every possible case:
match mySnack with
| Apple a -> printfn "An apple: %A" a
| Banana b -> printfn "A banana: %A" b
| Cherries c -> printfn "Cherries: %A" c
why the tags? imagine two cases that both carry a string. without tags, the compiler can't tell which is which. tags are the labels that make each case unique.
an algebraic type system
an algebraic type system is one where all complex types are built by combining smaller types using AND or OR.
that's F#'s type system. the word "algebraic" just refers to this AND/OR algebra of combining types. the same logical words you used to describe your domain in natural language. this is exactly why F# types map so naturally to domain models.
putting together a real domain model
example of a payments domain in F#:
// Simple wrappers (give primitive types meaningful names)
type CheckNumber = CheckNumber of int
type CardNumber = CardNumber of string
// Low-level building blocks
type CardType = Visa | Mastercard // OR type
type CreditCardInfo = { // AND type
CardType : CardType
CardNumber: CardNumber
}
// Mid-level: payment can be cash, check, or card
type PaymentMethod =
| Cash
| Check of CheckNumber
| Card of CreditCardInfo
// More primitives
type PaymentAmount = PaymentAmount of decimal
type Currency = EUR | USD
// Top-level: a complete payment record
type Payment = {
Amount : PaymentAmount
Currency: Currency
Method : PaymentMethod
}
no behavior is attached to any of these, just shapes of data. behavior lives in separate functions.
to document what the system does, you define function types:
type PayInvoice = UnpaidInvoice -> Payment -> PaidInvoice
type ConvertPaymentCurrency = Payment -> Currency -> Payment
these are contracts. they say what goes in and what comes out, before a single implementation line is written.
three special situations
optional values
F# types can't be null by default, that's a feature, not a bug. if something might be missing, you wrap it in Option:
type Option<'a> =
| Some of 'a // there is a value
| None // there is no value
example of a name where the middle initial is optional:
type PersonalName = {
FirstName : string
MiddleInitial: string option // "string option" = Option<string>
LastName : string
}
this is much clearer than hoping someone remembers to check for null.
errors
instead of throwing exceptions, you can make failure a first-class part of a function's return type using Result:
type Result<'Success, 'Failure> =
| Ok of 'Success
| Error of 'Failure
a function that can fail:
type PayInvoice = UnpaidInvoice -> Payment -> Result<PaidInvoice, PaymentError>
type PaymentError =
| CardTypeNotRecognized
| PaymentRejected
| PaymentProviderOffline
now the caller must handle both outcomes, the type system enforces it.
no return value
when a function has nothing to return (like "save this to the database"), F# uses unit instead of void. the only value of type unit is written ():
type SaveCustomer = Customer -> unit
when you see unit in a signature, it's a signal that something is happening as a side effect, writing to a database, printing to screen, etc.
how lists work
for modeling collections, use list. it is immutable, readable, and composes well:
type Order = {
OrderId: OrderId
Lines : OrderLine list // a list of order lines
}
let myList = [1; 2; 3] // note: semicolons, not commas
let extended = 0 :: myList // prepend → [0; 1; 2; 3]
pattern matching on lists:
match myList with
| [] -> "empty"
| [x] -> "exactly one element"
| first :: rest -> "first element plus more"
one rule about ordering
F# requires types to be defined before they are used. simpler types go at the top of a file, complex types that depend on them go below. a typical project layout:
Common.Types.fs
Common.Functions.fs
OrderTaking.Types.fs
OrderTaking.Functions.fs
within a file, put primitive wrappers first, compound types in the middle, and top-level types at the bottom. if you're still sketching and want to write top-down, use module rec to temporarily relax this rule, then clean up the order when the design settles.
the big picture
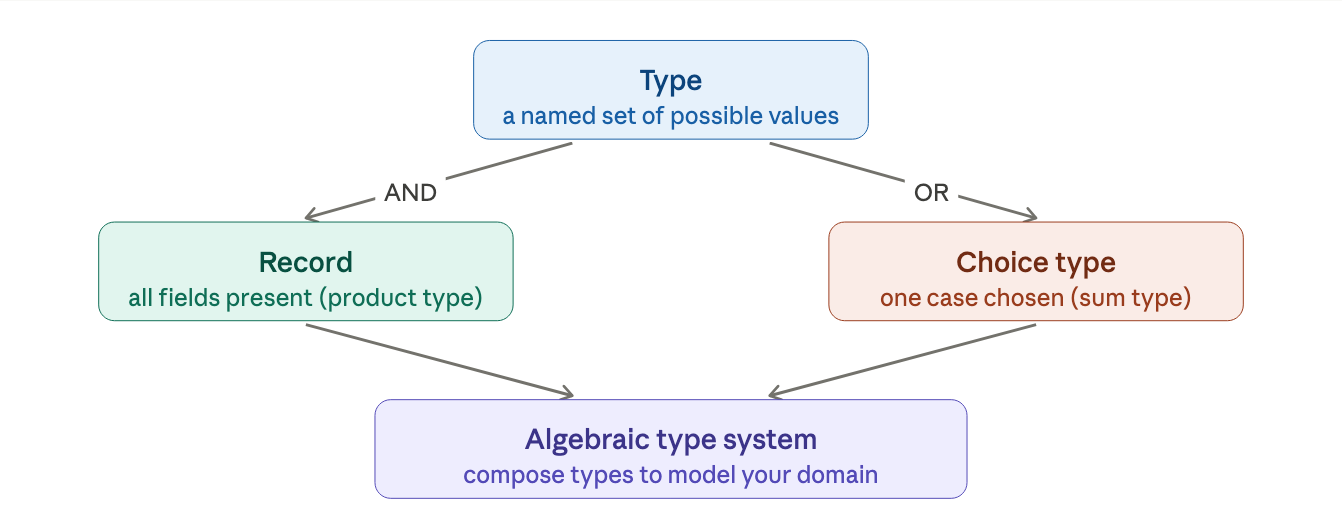
a type is a set of values. AND gives you records (everything required). OR gives you choice types (one option selected). combine these two primitives and you can describe virtually any domain concept in code, clearly, concisely, and in a way the compiler can actually enforce.
domain modeling with types
code can be the documentation by using type system for modeling the domain.
the problem: code and domain drift apart
in most codebases, there's a painful translation layer. a business analyst writes "an Order has a Customer, a list of OrderLines, and a total price." a developer then writes some classes involving strings, ints, and lists, and the two descriptions slowly diverge over time.
the goal here is to eliminate that gap entirely. we want F# types that a domain expert could read and say "yes, that's exactly what we mean."
pattern 1 - simple values
the first building block is the simplest: primitives values that mean something specific in the domain.
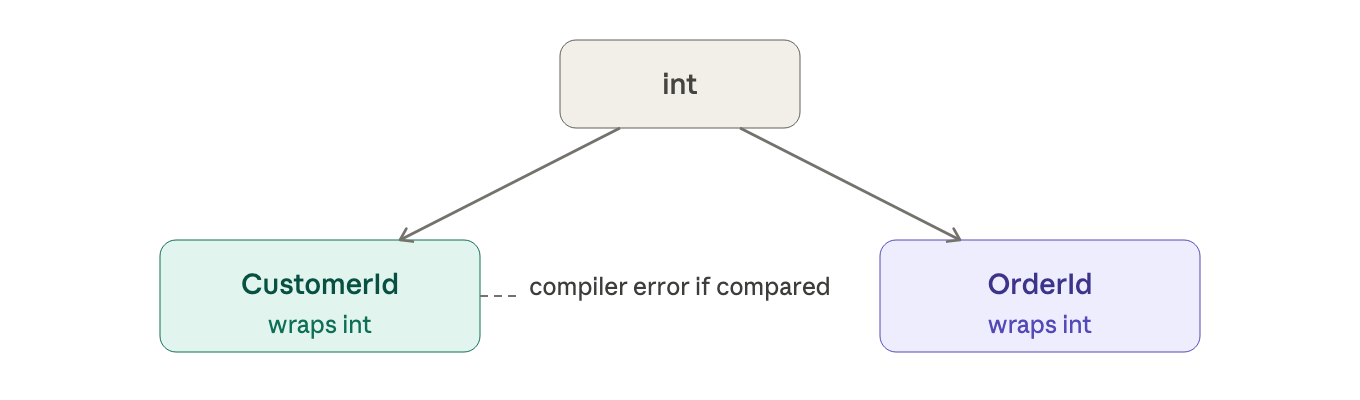
a naive approach uses raw primitives:
let customerId = 42 // int
let orderId = 42 // also int — oops
these are interchangeable to the compiler, but they shouldn't be. passing an orderId where a customerId is expected is a real bug.
the fix is to wrap each concept in its own type:
type CustomerId = CustomerId of int
type OrderId = OrderId of int
now the compiler enforces the distinction. these are called single-case union types, choice type with only one choice, used purely as a named wrapper.
creating and unwrapping these types is simple:
let id = CustomerId 42 // wrap: use the case name as a constructor
let (CustomerId inner) = id // unwrap: pattern match to get the int back
pattern 2 - AND types (records)
when several pieces of data always travel together, you group them. the domain documentation might say:
data Order =
CustomerInfo
AND ShippingAddress
AND BillingAddress
AND list of OrderLines
this maps directly to an F# record:
type Order = {
CustomerInfo : CustomerInfo
ShippingAddress : ShippingAddress
BillingAddress : BillingAddress
OrderLines : OrderLine list
AmountToBill : BillingAmount
}
notice we're using domain words (CustomerInfo, BillingAmount), not developer words (string, decimal). this keeps the code readable to non-developers.
tip for unknowns: during early stage design, you won't know what every type looks like internally. use a placeholder.
type Undefined = exn // a stand-in until you figure it out
type CustomerInfo = Undefined
type ShippingAddress = Undefined
this lets the code compile and forces you to fill in details as your understanding grows.
pattern 3 - OR types (choices)
some domain concepts are "one of several things":
data ProductCode = WidgetCode OR GizmoCode
this maps to a discriminated union:
type ProductCode =
| Widget of WidgetCode
| Gizmo of GizmoCode
each case has a tag (Widget, Gizmo) and associated data. the compiler forces you to handle all cases when pattern-matching, no forgotten branches.
 ### pattern 4 - workflows as functions
### pattern 4 - workflows as functions
business processes are modeled as function types, a type that says "take X, produces Y":
type ValidateOrder = UnvalidatedOrder -> ValidatedOrder
that one line tells you: this process turns an unvalidated order into a validated one.
multiple outputs? wrap them in a record:
type PlaceOrderEvents = {
AcknowledgmentSent : AcknowledgmentSent
OrderPlaced : OrderPlaced
BillableOrderPlaced : BillableOrderPlaced
}
type PlaceOrder = UnvalidatedOrder -> PlaceOrderEvents
things that can fail? use Result:
type ValidateOrder =
UnvalidatedOrder -> Result<ValidatedOrder, ValidationError list>
now the type signature documents that failure is possible, no need for comments or external docs.
async operations? layer Async on top:
type ValidateOrder =
UnvalidatedOrder -> Async<Result<ValidatedOrder, ValidationError list>>
clean it up with a type alias:
type ValidationResponse<'a> = Async<Result<'a, ValidationError list>>
type ValidateOrder = UnvalidatedOrder -> ValidationResponse<ValidatedOrder>
value objects vs entities
value objects have no identity, they are defined purely by their content. two addresses with the same street, city, and zip are the same address. in F#, record types give you this for free: equality checks all fields.
let address1 = { Street = "123 Main St"; City = "NY"; Zip = "10001" }
let address2 = { Street = "123 Main St"; City = "NY"; Zip = "10001" }
address1 = address2 // true ✓
entities have a persistent identity that survives changes. a customer is still the same customer even after changing their email. you track them by ID, not by content.
let address1 = { Street = "123 Main St"; City = "NY"; Zip = "10001" }
let address2 = { Street = "123 Main St"; City = "NY"; Zip = "10001" }
address1 = address2 // true ✓
for entities, it is recommended to add [<NoEquality; NoComparison>] to disallow default equality entirely. this forces you to be explicit: instead of contact1 = contact2, you write contact1.ContactId = contact2.ContactId. no ambiguity about what "equal" means.
aggregates - the consistency boundary
here's a subtle but critical concept. consider Order and OrderLine.
- both are entities (both have IDs).
- but if you change an order line, the order has changed too.
- with immutable data, you can't just modify the line in isolation, you must rebuild the whole order with the new line inside it.
this grouping, where changes must ripple through a single top-level entity, is called an aggregate. the top-level entity is the aggregate root.
let changeOrderLinePrice order orderLineId newPrice =
let orderLine = order.OrderLines |> findOrderLine orderLineId
let newOrderLine = { orderLine with Price = newPrice }
let newLines = order.OrderLines |> replaceOrderLine orderLineId newOrderLine
{ order with OrderLines = newLines } // returns a new Order
this function's output is a brand new Order, not a mutation of the old one. immutability makes this ripple effect explicit and safe.
a key rule: other aggregates should only reference you by ID, never by embedding the full object. so Order stores a CustomerId, not a whole Customer. if you embed the full Customer, any change to the customer forces a change to every order too, a massive ripple effect you don't want.
aggregates are also the unit of persistence: you load and save a whole aggregate at once, in one database transaction.
putting it all together
namespace OrderTaking.Domain
// --- Simple types ---
type WidgetCode = WidgetCode of string // starts with "W" + 4 digits
type GizmoCode = GizmoCode of string // starts with "G" + 3 digits
type ProductCode = Widget of WidgetCode | Gizmo of GizmoCode
type UnitQuantity = UnitQuantity of int
type KilogramQuantity = KilogramQuantity of decimal
type OrderQuantity = Unit of UnitQuantity | Kilos of KilogramQuantity
// --- IDs (details TBD) ---
type OrderId = Undefined
type OrderLineId = Undefined
type CustomerId = Undefined
// --- Order aggregate ---
type Order = {
Id : OrderId
CustomerId : CustomerId // reference only — not the full Customer
ShippingAddress : ShippingAddress
BillingAddress : BillingAddress
OrderLines : OrderLine list
AmountToBill : BillingAmount
}
and OrderLine = {
Id : OrderLineId
OrderId : OrderId
ProductCode : ProductCode
OrderQuantity : OrderQuantity
Price : Price
}
// --- Workflow ---
type PlaceOrderEvents = {
AcknowledgmentSent : AcknowledgmentSent
OrderPlaced : OrderPlaced
BillableOrderPlaced : BillableOrderPlaced
}
type PlaceOrderError =
| ValidationError of ValidationError list
// other error cases...
and ValidationError = {
FieldName : string
ErrorDescription : string
}
type PlaceOrder =
UnvalidatedOrder -> Result<PlaceOrderEvents, PlaceOrderError>
the final line, type PlaceOrder = UnvalidatedOrder -> Result<PlaceOrderEvents, PlaceOrderError>, is the whole workflow in a single, readable sentence.
why this matters
the design is the code.
traditional design → implementation pipelines have a fatal flaw: the diagram and the code diverge. with this approach, if the domain model changes and you update the types, the compiler immediately tells you everywhere in the codebase that needs to change. the design can never silently drift from the implementation.
a non-developer reading these types definitions needs to learn only four things: wrapper types, records with {}, choices with |, and function with ->. that's a small enough vocabulary to make he code genuinely reviewable by domain experts.
integrity and consistency in the domain
once you have built a domain model, you need to make sure that the data living inside it is always trustworthy.
a trusted inner world
think of your domain as a walled city. outside is chaos, raw user input, external APIs, messy databases. inside should be peace: data you can always trust. the boundary betwee the two is called the bounded context.

the goal is to validate once at the border, then never check it again. every type inside the boundary is a promise that if a value exist, it is already valid.
part 1: integrity
why int and string aren't enough
the problem with using raw primitives is they're too broad.
- an
intcan be-4,000,000,000. aUnitQuantitycan't. - a
stringcan contain tabs, null bytes, or be empty. aProductCodeshouldn't.
the fix is constrained types, wrappers that only allow valid values in.
the smart constructor pattern
the trick is making the constructor private, so there's only one way in, through a validation function that returns success or failure:
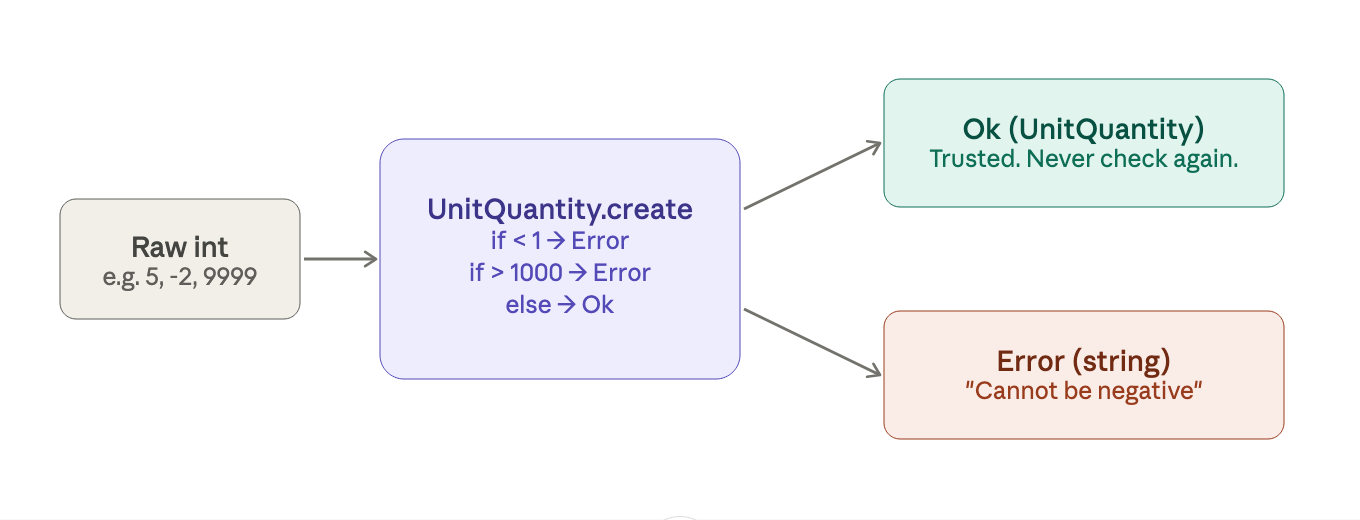
in F#, this looks like:
type UnitQuantity = private UnitQuantity of int
module UnitQuantity =
let create qty =
if qty < 1 then Error "Cannot be negative"
elif qty > 1000 then Error "Cannot exceed 1000"
else Ok (UnitQuantity qty)
let value (UnitQuantity qty) = qty // unwrap when you need the raw int
the private keyword locks the constructor, nobody can write UnitQuantity 42 from outside this module. the only way to get a UnitQuantity is through create, which forces you to handle the error case. once you have one, you'll never need to validate again.
part 2: using the type system as a rulebook
enforcing "must have at least one item"
some rules aren't about a value's range, they are about structure. "an order must always have at least one order line" is one of them.
instead of an OrderLine list (which can be empty), define a type that structurally cannot be empty:
type NonEmptyList<'a> = {
First: 'a
Rest: 'a list
}
the definition itself enforces the rule. First is always required. you get a compile-time guarantee with zero runtime checks.
making illegal states unrepresentable
this is the big idea of the chapter. the question to ask is: can this invalid situation even be constructed? if yes, find a way to make it impossible to construct.
example: verified vs. unverified email
a naive approach uses a boolean flag:
type CustomerEmail = {
EmailAddress : EmailAddress
IsVerified : bool // ← easy to misuse
}
the problem is that a developer could accidentally set IsVerified = true for an email that was never actually verified. the rule lives in comments, not in the compiler.
a better approach models them as two distinct types:
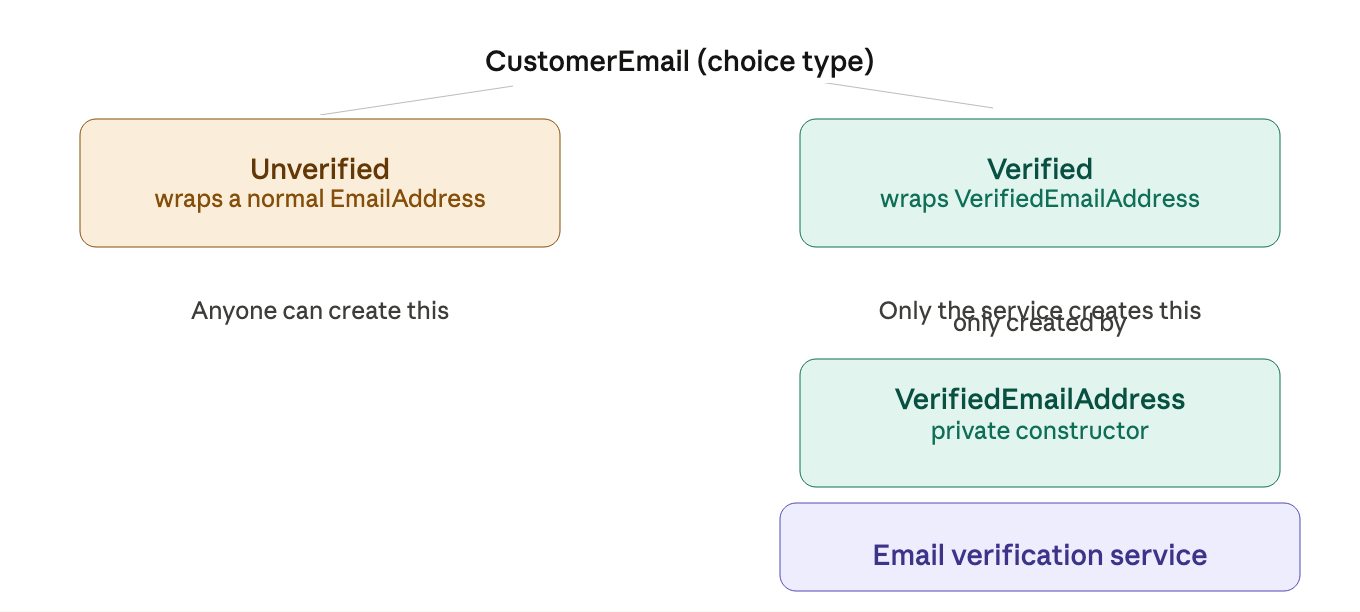
now the rule is physical. you literally cannot construct a Verified email without a VerifiedEmailAddress, and you can only get one of these from the verification service. no accidental bypasses.
and you can now write a function like this:
type SendPasswordResetEmail = VerifiedEmailAddress -> ...
the function signature is the documentation. pass it a normal EmailAddress and the compiler says no.
example: "must have email or postal address"
a contact must have at least one way to reach them. using two optional fields doesn't enforce this:
// Bad — both can be None at the same time
type Contact = {
Email : EmailContactInfo option
Address : PostalContactInfo option
}
instead, enumerate the three valid states explicitly:
type ContactInfo =
| EmailOnly of EmailContactInfo
| AddrOnly of PostalContactInfo
| EmailAndAddr of EmailContactInfo * PostalContactInfo
there are exactly three valid states. the fourth state (neither) cannot be represented. the compiler enforces the rule for free, forever.
part 3: consistency
integrity is about individual values. consistency is about values agreeing with each other.
consistency within one aggregate
an aggregate is a cluster of related objects treated as a single unit. the key rule is to only update through the root of the aggregate.
for example, if an order has a stored AmountToBill, that total must always equal the sum of all order lines. the only way to guarantee this is to always update the total whenever a line is changed, and to do both in one operation:
let changeOrderLinePrice order lineId newPrice =
let updatedLines = order.OrderLines |> replaceLinePrice lineId newPrice
let newTotal = updatedLines |> List.sumBy (fun l -> l.Price)
{ order with OrderLines = updatedLines; AmountToBill = newTotal }
the order is the aggregate root. it knows how to keep itself consistent. nothing should reach inside and change just one piece.
consistency across different context
what about two separate systems that need to agree, like an order system and a billing system that must both have records of the same order?
the naive approach (do both operations in one transaction) breaks quickly across network boundaries. the real-world approach is eventual consistency: instead of demanding everything updates instantly, you should accept a brief window of inconsistency and close it asynchronously.
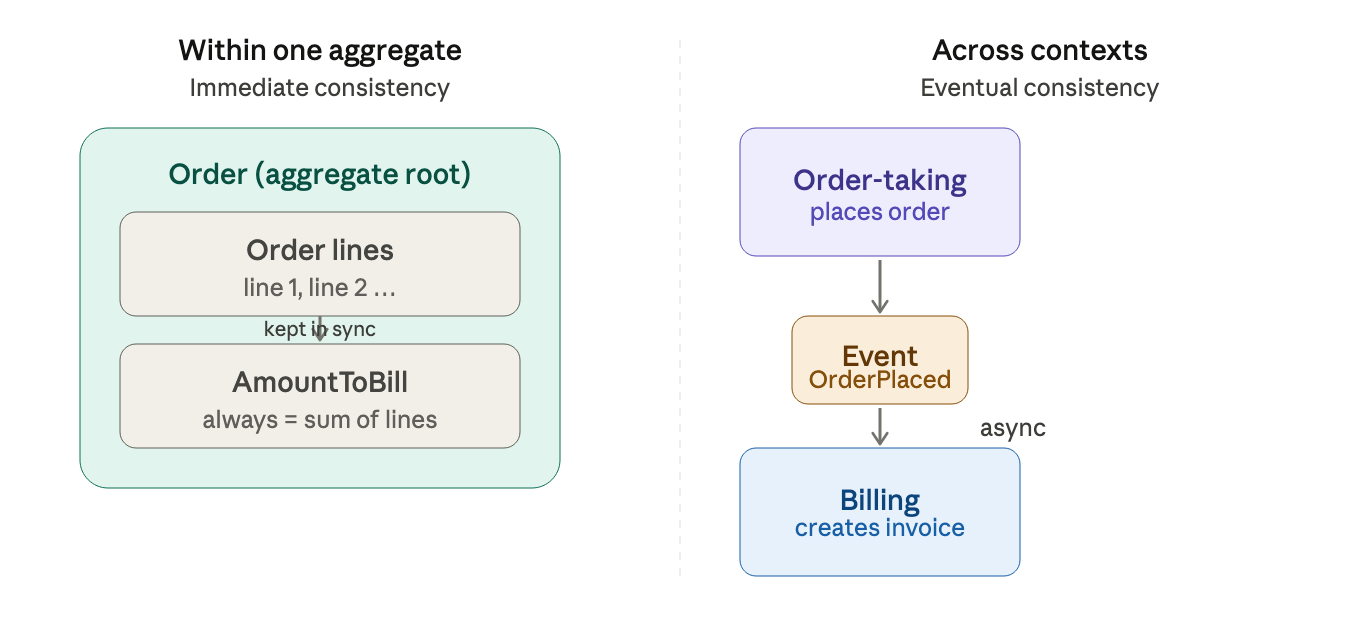
the key insight (borrowed from a famous essay about Starbuck): in the real world, most business don't demand lockstep coordination between every system. a coffee shop doesn't stop serving until the accounting software confirm the sale. things move forward, errors are rare, and when they happen you fix them, with a reconciliation process or a compensating action like issuing a refund or canceling an order.
"eventual consistency" isn't sloppy, it just means the system will reach a consistent state, just not necessarily right this millisecond.
modeling workflows as pipelines
what is a workflow?
a workflow is a data being transformed from one shape into another. in an order taking workflow, for example, an unverified order goes in. a confirmed order with pricing and an acknowledgment email comes out. everything in between is a series of transformations, each step takes data, does one thing to it, and passes it along.
this is called transformation-oriented programming, and it maps beautifully to functional programming.
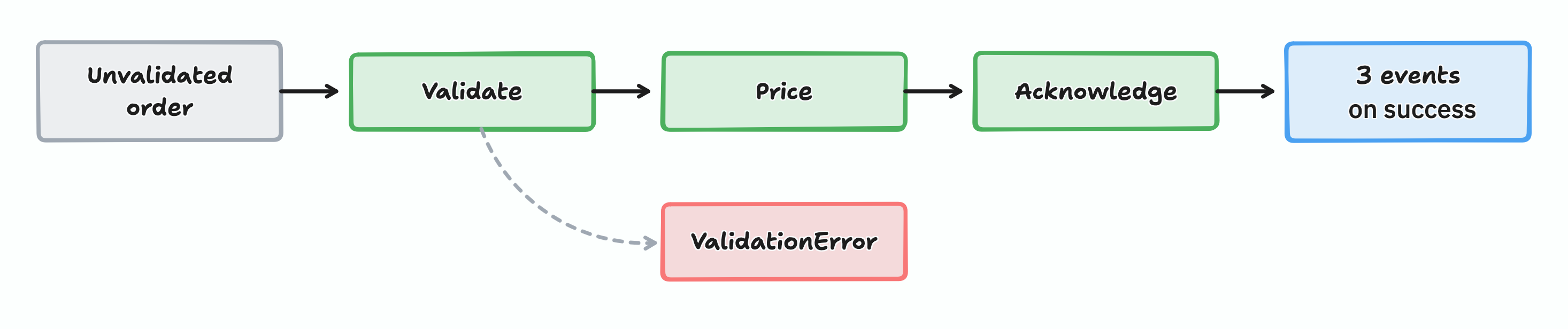
part 1 - the input (commands)
something has to cause the workflow to run and that is what command does. a command says: "do this".
commands carry:
- the data needed to do the work (e.g. the order form)
- who asked for it (
UserId) - when they asked (
Timestamp)
sharing structure with generics
since every commands has the same metadata, instead of repeating UserId and Timestamp in every command type, you define a generic wrapper:
type Command<'data> = {
Data : 'data
Timestamp : DateTime
UserId : string
}
type PlaceOrderCommand = Command<UnvalidatedOrder>
this is the function equivalent of inheritance. think of Command<'data> as a labeled envelope, and 'data as whatever you put inside.
routing multiple commands
type OrderTakingCommand =
| Place of PlaceOrder
| Change of ChangeOrder
| Cancel of CancelOrder
a dispatcher reads this type and routes each case to the right workflow.
part 2 - modeling with state machine
the naive approach
imagine modeling an order with a single record that tracks all its possible states via flags:
type Order = {
IsValidated : bool
IsPriced : bool
AmountToBill : decimal option // only valid when IsPriced
}
this looks reasonable but it's actually a mess:
- states are implicit, you have to read the flags to figure out where you are
- data like
AmountToBillonly applies in some states, so it has to beoptioneverywhere - nothing stops you from having
IsPriced = truebutAmountToBill = None, a contradiction
the better approach with one type per state
instead, give each state its own type:
type ValidatedOrder = {
OrderId : OrderId
CustomerInfo : CustomerInfo
ShippingAddress : Address
OrderLines : ValidatedOrderLine list
}
type PricedOrder = {
OrderId : OrderId
CustomerInfo : CustomerInfo
ShippingAddress : Address
OrderLines : PricedOrderLine list // different line type
AmountToBill : BillingAmount // only exists here
}
then a top-level union type represents the order at any point in its life:
type Order =
| Unvalidated of UnvalidatedOrder
| Validated of ValidatedOrder
| Priced of PricedOrder
this is a state machine, a pattern where a thing moves through distinct, explicitly-named states triggered by events or commands.
why state machines are worth it
three concrete benefits:
- different states allow different behavior.
you can only pay for an active cart, not an empty one. you can only send a password reset to a verified email. the type system enforces this, you can't accidentally call
makePaymenton anEmptyCartbecause the function only acceptActiveCart. - all states are explicitly documented. implicit states (tracked only in your head) are where bugs live. when you define a type for each state, every possible condition is named and visible.
- edge cases must be handled.
what happens if you try to deliver a package already marked
Delivered? with a state machine, the code forces you to answer that question, every case in a union type must be handled.
implementing a simple state machine in F#
the shopping cart is the clearest example:
type Item = ...
type ActiveCartData = { UnpaidItems: Item list }
type PaidCartData = { PaidItems: Item list; Payment: float }
type ShoppingCart =
| EmptyCart
| ActiveCart of ActiveCartData
| PaidCart of PaidCartData
a command like "add item" becomes a function that can handles all three cases:
let addItem cart item =
match cart with
| EmptyCart -> ActiveCart { UnpaidItems = [item] }
| ActiveCart { UnpaidItems = existing } ->
ActiveCart { UnpaidItems = item :: existing }
| PaidCart _ -> cart // already paid — ignore
the caller always passes a ShoppingCart and gets a ShoppingCart back. internally, each state is handled separately.
part 3 - modeling each pipeline step with types
now we apply the state machine thinking to each step of the order workflow. model every step as a function signature before writing any implementation.
the validation step
from our domain documentation:
- input:
UnvalidatedOrder - output:
ValidatedOrderorValidationError - needs: a product-code checker and an address checker
dependencies are just functions too. we define their types as interfaces:
type CheckProductCodeExists =
ProductCode -> bool
type CheckAddressExists =
UnvalidatedAddress -> Result<CheckedAddress, AddressValidationError>
the full step signature then reads like a sentence:
type ValidateOrder =
CheckProductCodeExists // dependency
-> CheckAddressExists // dependency
-> UnvalidatedOrder // input
-> Result<ValidatedOrder, ValidationError list> // output
whey put dependencies first? so you can use partial application, the functional equivalent of dependency injection. you pre-fill the dependencies and get back a simpler function that just takes the order.
the pricing step
type GetProductPrice = ProductCode -> Price
type PriceOrder =
GetProductPrice // dependency
-> ValidatedOrder // input
-> PricedOrder // output (no Result — this always succeeds)
notice: no Result wrapper here, because this step is expected to succeed. the product catalog is assumed to be local and fast.
the acknowledge order step
this step creates a letter and sends it. two questions need answers upfront:
- how do we know what to write in the letter? we don't, and we shouldn't. we define a function that someone else will implement:
type CreateOrderAcknowledgmentLetter = PricedOrder -> HtmlString
- how do we know if the acknowledgement was actually sent? we need a meaningful return type, not
bool(too vague), notunit(no information). a custom two-case type is clearest:
type SendResult = Sent | NotSent
type SendOrderAcknowledgment =
OrderAcknowledgment -> SendResult
the full step:
type AcknowledgeOrder =
CreateOrderAcknowledgmentLetter // dependency
-> SendOrderAcknowledgment // dependency
-> PricedOrder // input
-> OrderAcknowledgmentSent option // output (might not have been sent)
creating the output events
at the end of the pipeline, we need to emit three events. rather than a fixed record (which is hard to extend), we use a union type as a list:
type PlaceOrderEvent =
| OrderPlaced of OrderPlaced
| BillableOrderPlaced of BillableOrderPlaced
| AcknowledgmentSent of OrderAcknowledgmentSent
type CreateEvents =
PricedOrder -> PlaceOrderEvent list
adding a new event later is just adding a new case, nothing else breaks.
part 4 - documenting effects (async & errors)
a function's effects, things it might do beyond just returning a value, should be visible in its type signature. the two main ones are:
Result<ok, err>, the function might failAsync<T>, the function does I/O and might be slow
applying this to keep step
the address checker calls a remote service. it can fail and it's async. these combine into AsyncResult:
type AsyncResult<'success, 'failure> = Async<Result<'success, 'failure>>
type CheckAddressExists =
UnvalidatedAddress -> AsyncResult<CheckedAddress, AddressValidationError>
like a virus, Async propagates upward. because CheckAddressExist is async, the whole ValidateOrder step becomes async:
type ValidateOrder =
CheckProductCodeExists
-> CheckAddressExists
-> UnvalidatedOrder
-> AsyncResult<ValidatedOrder, ValidationError list>
the pricing step might catch a mispriced item, so it gains a Result:
type PriceOrder =
GetProductPrice
-> ValidatedOrder
-> Result<PricedOrder, PricingError>
the send acknowledgment step does I/O but we don't care if it fails (we continue regardless):
type SendOrderAcknowledgment =
OrderAcknowledgment -> Async<SendResult>
part 5 - the complete public API
the public-facing workflow hides all internal dependencies. callers don't need to know about address validators or product catalogs:
type PlaceOrderWorkflow =
PlaceOrderCommand
-> AsyncResult<PlaceOrderEvent list, PlaceOrderError>
that's it. one input, one output. the messy internals are hidden.
internally, each step's dependencies are explicit (to guide implementation), but from the outside, the workflow is a clean black box.
part 6 - the competition challenge
here's the problem the chapter leaves you thinking about. look at the output of each step vs. the input of the next:
ValidateOrderoutputsAsyncResult<ValidatedOrder, ...>PriceOrderexpects justValidatedOrderas input
these don't connect directly. you can't just pipe one into the next. this is the challenge fof composing functions that have Result and Async wrappers, and solving it (using monadic composition / railway-oriented programming) is what the next chapters cover.
part 7 - long-running workflows
everything above assumes the pipeline completes in seconds. but what if validation requires a human? or pricing takes a day?
then you need a long-running workflow (sometimes called a Saga):
- before each step, save the state to storage
- after each step completes (possibly via an event from another system), restore state from storage and continue
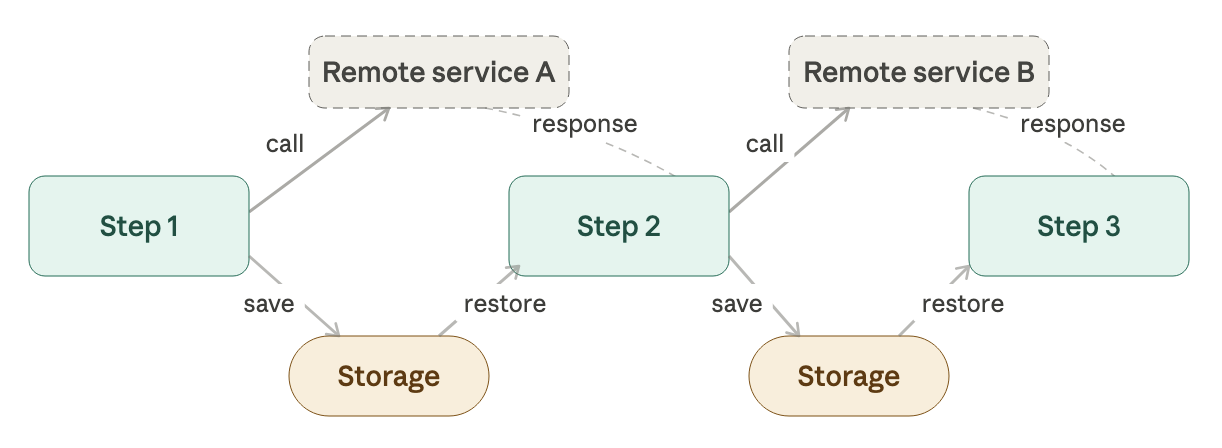
the state machine model is exactly what makes this work. because the order is always in a named state (Unvalidated, Validated, Priced), you can serialize it, store it, come back days later, deserialize it, and continue, because the state type tells you exactly where you left off.
when the transitions get complex, you'd introduce a Process Manager, a dedicated component that tracks which events have arrived and which workflow steps to trigger next.
understanding functions
functions everywhere
in functional programming, functions are more than tools you call to do something, they are also values just like numbers or strings. they can be passed around, stored in lists, and build new functions from old ones.
this way of thinking changes how we design a program.
what is a function?
a function is a box with a rule: give me this, i'll give you that. input goes in, output comes out. the rule never changes: same input, same output, every time.
predictability is what makes functions powerful building blocks. you can reason about them in isolation, combine them safely, and trust that nothing surprising happens inside.
functions as tings
in F# (and functional languages generally), a function is just a value.
- a function can be an input
- a function can be an output
- a function can be a parameter (control behavior)
in F# code, these ideas look like this:
// A plain function
let add1 x = x + 1
// A function that TAKES a function as input
let evalWith5ThenAdd2 fn =
fn(5) + 2
// type: fn:(int -> int) -> int
// Pass add1 in — it works
evalWith5ThenAdd2 add1 // → 8
// A function FACTORY that returns new functions
let adderGenerator numberToAdd =
fun x -> numberToAdd + x
// type: int -> (int -> int)
let add100 = adderGenerator 100
add100 2 // → 102
functions that take or return other functions are called higher-order functions (HOFs). they're the core tool of FP design.
currying: every function secretly takes one argument
in F#, a function that appears to take two parameters is actually two nested one-parameter functions:
// Looks like two params...
let add x y = x + y
// ...but is really this underneath:
let add x = fun y -> x + y
this is called currying, where you can always pass fewer arguments than a function expects. you get back a new function waiting for the rest. this is called partial application.
let sayGreeting greeting name =
printfn "%s %s" greeting name
// Partially apply — only pass the greeting
let sayHello = sayGreeting "Hello" // still needs a name
let sayGoodbye = sayGreeting "Goodbye" // still needs a name
sayHello "Alex" // → "Hello Alex"
sayGoodbye "Alex" // → "Goodbye Alex"
this is how FP does dependency injection, instead of passing in an interface, you pass a functino with some context already baked in.
total functions: type signatures that don't lie
a function is total if every possible input has a valid output, no exceptions, no surprises, no hidden failure modes.
consider this function:
// This looks honest...
let twelveDividedBy n : int -> int
but if n is zero, it throws an exception. the signature promises an int every time, but that's a lie. the actual behavior is: "sometimes an int, sometimes a crash."
there are two honest ways to fix this:
- restrict the input. only allow values that are actually valid
type NonZeroInteger = private NonZeroInteger of int
let twelveDividedBy (NonZeroInteger n) : int =
match n with
| 6 -> 2
| ...
// Signature: NonZeroInteger -> int ✓ Never crashes
- extend the output. accept anything, but signal when there's no answer.
let twelveDividedBy n : int option =
match n with
| 0 -> None // No answer for zero
| n -> Some (12 / n) // Valid answer otherwise
// Signature: int -> int option ✓ No hidden crashes
the option type is F#'s way of saying "this might not exist." Some 6 means "here's the value."
None means "no value." the signature tells you upfront, you have to handle both cases.
composition: building big things fro small things
this is the centerpiece of the whole chapter. in FP, you build software the way you build with LEGO, small pieces that snap together.
the rule is simple: the output type of one function must match the input type of the next.
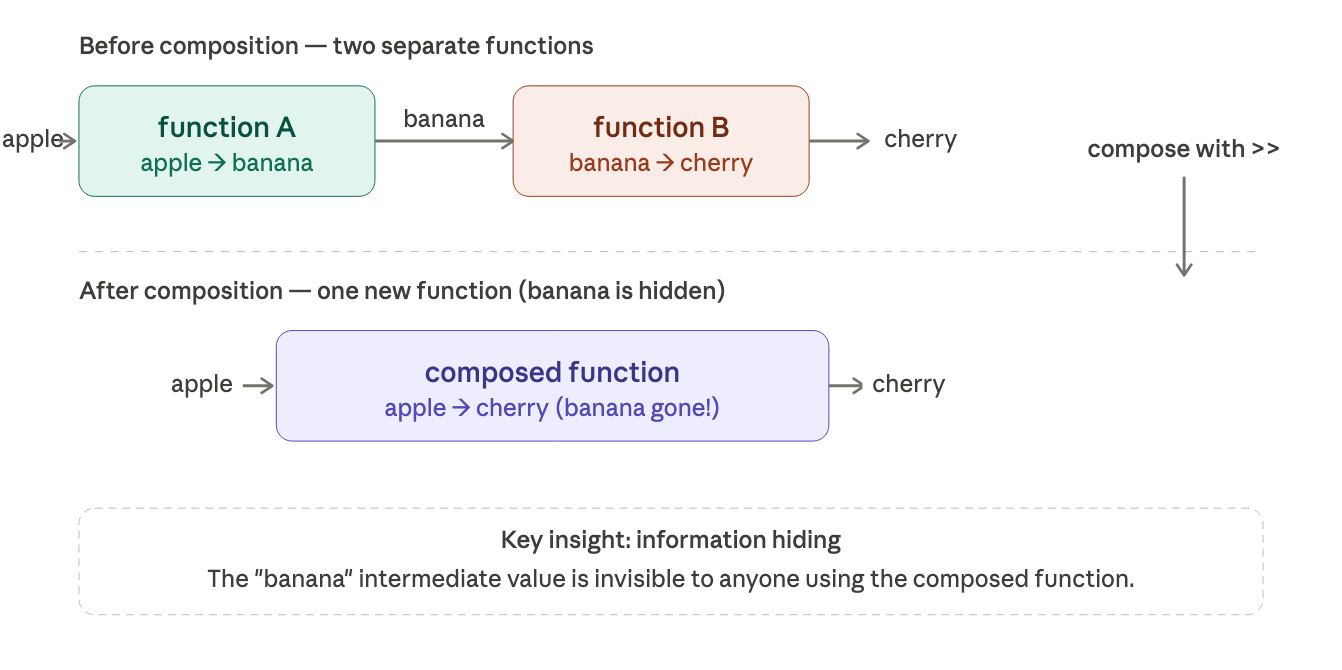
in F#, composition uses the pipe operator |>. you start with a value and pass it through a chain of functions, left to right:
let add1 x = x + 1 // int -> int
let square x = x * x // int -> int
let isEven x = (x % 2) = 0 // int -> bool
let printBool x = sprintf "value is %b" x // bool -> string
// Piping: each output feeds the next input
let add1ThenSquare x = x |> add1 |> square
add1ThenSquare 5 // → 36
let isEvenThenPrint x = x |> isEven |> printBool
isEvenThenPrint 2 // → "value is true"
think of it like a conveyor belt. the value starts at one end and travels through each processing station in order. the |> operator just means "hand this to the next function."
scaling up: building an entire application
the same composition principle works at every level. you don't just compose two tiny functions, you compose entire layers of an application.
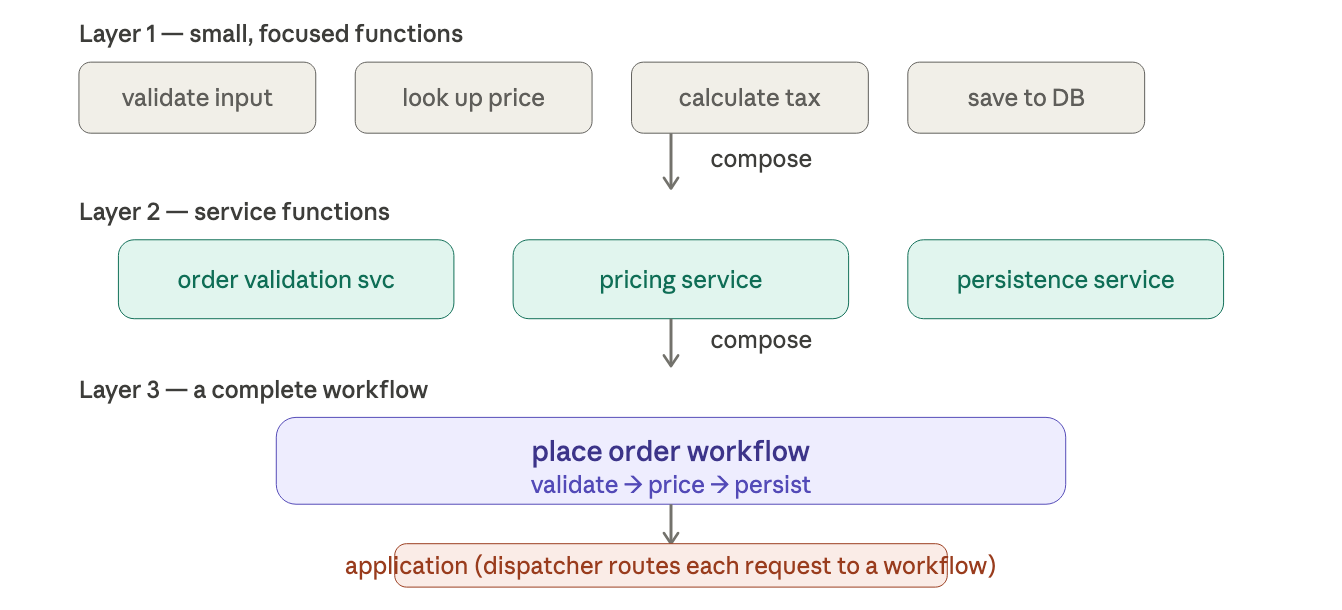
each layer is just a function: input in, output out. the application is functions all the way up. this is the FP equivalent of object-oriented layered architecture with just pipelines.
when types don't match: the composition challenge
composition is easy when types line up. but often they don't. one function outputs an int, and the next expects an Option<int> or vice versa.
functionA → int ✗ Option<int> → functionB (mismatch!)
the solution is to bring both sides to a common type. if one side produces a plain int and the other expects Option<int>, wrap the int in Some:
let add1 x = x + 1 // int -> int
let printOption x = // Option<int> -> unit
match x with
| Some i -> printfn "Got %i" i
| None -> printfn "Nothing"
// Bridge the gap by wrapping with Some
5 |> add1 |> Some |> printOption // → "Got 6"
the same kind of mismatch appears with Result (success vs failure), lists, async operations, and more. much of practical FP is learning the patterns for bridging these mismatches so functions can be composed cleanly.
building a pipeline
the pipeline at a glance
think of it like a factory assembly line. a raw, unverified order walks in one end. at each station, something gets added or checked. a fully-formed bundle of events walks out the other end.

simple types need guardrails
before building the pipeline steps, we need safe building blocks, types like OrderId or ProductCode that can only ever hold valid values.
each simple type gets two helpers:
create that takes a raw string/number, validates it, and either returns a valid value or throws an error. value that unwraps the type back to its raw primitive when you need it.
// OrderId can only be a non-empty string under 50 chars
let create str =
if String.IsNullOrEmpty(str) then failwith "OrderId must not be empty"
elif str.Length > 50 then failwith "OrderId too long"
else OrderId str
// Pull the string back out when needed
let value (OrderId str) = str
the pattern-match trick in value, putting (OrderId str) directly in the parameter, unwraps it in one step.
step 1: validation
the validation step's job: take an UnvalidatedOrder (raw strings from the outside world) and produce a ValidatedOrder (fully checked domain objects).
the recipe: for every field in the unvalidated order, run the corresponding create helper, then assemble them into the validated record.
let validateOrder checkProductCodeExists checkAddressExists unvalidatedOrder =
let orderId = unvalidatedOrder.OrderId |> OrderId.create
let customerInfo = unvalidatedOrder.CustomerInfo |> toCustomerInfo
let shippingAddr = unvalidatedOrder.ShippingAddress |> toAddress checkAddressExists
let lines = unvalidatedOrder.Lines |> List.map (toValidatedOrderLine checkProductCodeExists)
{ OrderId=orderId; CustomerInfo=customerInfo; ShippingAddress=shippingAddr; Lines=lines }
toCustomerInfo and toAddress are small helper functions that do the same thing one level deeper, take an unvalidated sub-object, validate each of its fields, return trusted one.
the adapter problem, when a function returns the wrong thing
checkProductCodeExists returns a bool (does this product exist?). but in our pipeline we need it to return the product code itself. returning a bool breaks the chain.
the fix: write a tiny adapter function that wraps any predicate into a "pass-through or fail" function.
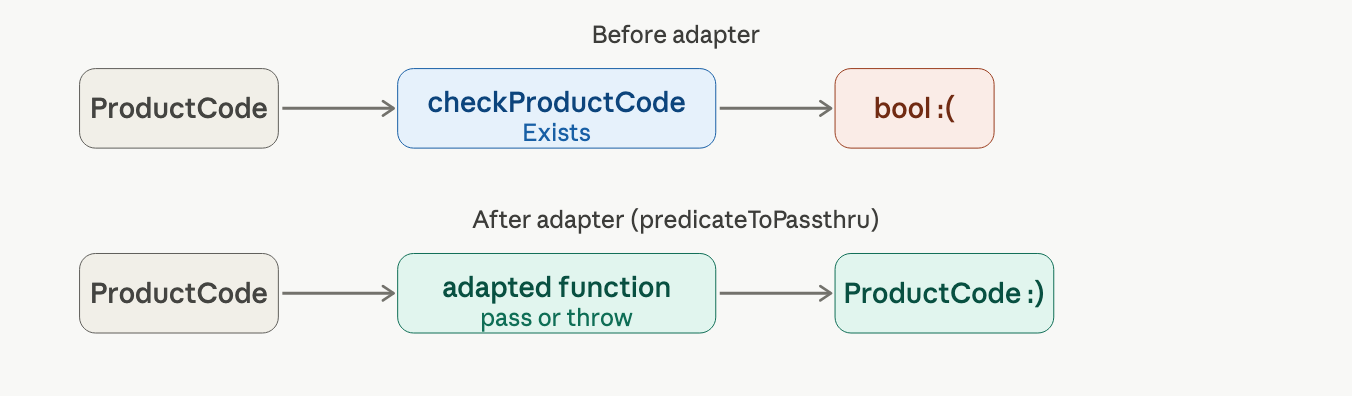
the adapter is generic, it works for any predicate:
let predicateToPassthru errorMsg f x =
if f x then x // passes? return the value unchanged
else failwith errorMsg // fails? throw
notice the F# compiler inferred this as string -> (a' -> bool) -> 'a -> 'a, it doesn't mention ProductCode at all. you accidentally wrote a universal utility.
step 2: pricing, adding totals
the pricing step takes a ValidatedOrder and produces a PricedOrder. it calls getProductPrice for each order line, multiplies price x quantity, and sums everything into a BillingAmount.
let priceOrder getProductPrice validatedOrder =
let lines = validatedOrder.Lines |> List.map (toPricedOrderLine getProductPrice)
let amountToBill = lines |> List.map (fun l -> l.LinePrice) |> BillingAmount.sumPrices
{ ...validatedOrder fields...; Lines=lines; AmountToBill=amountToBill }
the OrderQuantity wrinkle: a product can be measured in units (whole numbers, for widgets) or kilograms (decimals, for gizmos). the code matches on the product type to pick the right constructor, and then lifts both cases into the common OrderQuantity type so the compiler stays happy.
step 3: acknowledgment
simple: create the letter, send it, return an event only if it was actually sent.
let acknowledgeOrder createLetter sendAcknowledgment pricedOrder =
let letter = createLetter pricedOrder
let ack = { EmailAddress = pricedOrder.CustomerInfo.EmailAddress; Letter = letter }
match sendAcknowledgment ack with
| Sent -> Some { OrderId=pricedOrder.OrderId; EmailAddress=... }
| NotSent -> None
the result is an option, Some event or None. this is honest: sometimes the email doesn't go through, and the types reflect that.
step 4: create events
three things need to go into the output:
OrderPlacedOrderAcknowledgment(only if the email was sent, it's anoption)BillableOrderPlaced(only if the total is > $0, also anoption)
the strategy: lift everything to the same type, then combine into one list.
let createEvents pricedOrder acknowledgmentOpt =
let event1 = pricedOrder |> PlaceOrderEvent.OrderPlaced |> List.singleton
let event2 = acknowledgmentOpt |> Option.map PlaceOrderEvent.AcknowledgmentSent |> listOfOption
let event3 = pricedOrder |> createBillingEvent |> Option.map PlaceOrderEvent.BillableOrderPlaced |> listOfOption
[ yield! event1; yield! event2; yield! event3 ]
listOfOption is a tiny helper: Some x -> [x], None -> []. now all three are plain lists of the same type and you can combine them trivially.
the hard part: connecting steps that don't fit
the ideal pipeline:
unvalidatedOrder |> validateOrder |> priceOrder |> acknowledgeOrder |> createEvents
the problem: validateOrder need two extra inputs (the two dependency function), and acknowledgeOrder's output doesn't match createEvents's input.
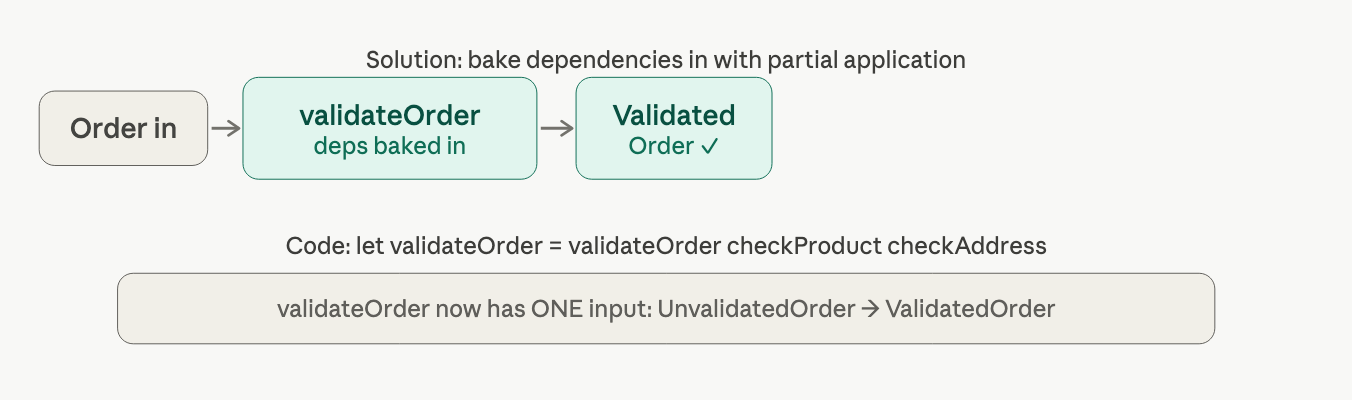
partial application is the fix. you can call a function with only some of its arguments, getting back a new function that's waiting for the rest.
// validateOrder normally needs 3 arguments.
// We feed it 2, and get back a 1-argument function.
let validateOrder = validateOrder checkProductCodeExists checkAddressExists
// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
// dependencies "baked in"
now validateOrder takes exactly one input (UnvalidatedOrder) and returns one output (ValidatedOrder). it snaps into the pipe.
writing the full pipeline
because acknowledgeOrder returns an option (not a PricedOrder), the pure pipe doesn't work for the last two steps. switch to explicit assignment, still clean, still readable:
let placeOrder unvalidatedOrder =
let validatedOrder =
unvalidatedOrder |> validateOrder checkProductExists checkAddressExists
let pricedOrder =
validatedOrder |> priceOrder getProductPrice
let acknowledgmentOption =
pricedOrder |> acknowledgeOrder createLetter sendAcknowledgment
createEvents pricedOrder acknowledgmentOption
where do the dependencies come from?
each function gets its dependencies as explicit parameters, passed in from the function above it. this chain reaches all the way up to a single composition root at the top of you app.
// In your app's startup / composition root:
let checkProductExists = ... // real database call
let checkAddressExists = ... // real HTTP call
let getProductPrice = ... // real pricing service
// Hand everything to the workflow once, upfront.
let placeOrder = placeOrder checkProductExists checkAddressExists getProductPrice ...
if a low-level function (say checkAddressExists) needs its own dependencies (a URL, credentials), you bake those in at the composition root too, so only clean one-argument version gets passed into the pipeline. middle layers never need to know about configuration details they don't use.
why this makes testing trivially easy
because every dependency is an explicit parameter, tests just pass in fake functions:
// Success case: pretend the product always exists
let checkProductCodeExists _ = true
let result = validateOrder checkProductCodeExists checkAddressExists testOrder
// Failure case: pretend it never does
let checkProductCodeExists _ = false
let result = validateOrder checkProductCodeExists checkAddressExists testOrder
no mocking frameworks. no test containers. no surprises. the function is stateless, same inputs always produce the same outputs, so testing is just calling a function.
three techniques to remember
| technique | what it solves | how |
|---|---|---|
| adapter function | function returns wrong type for the pipeline | wrap it so it returns the input value (or fails) |
| lifting | mismatched types (option, list, choice type) | convert everything to a common type before combining |
| partial application | extra dependency parameters break composition | pre-apply the dependencies, get a clean single-input function |
handling errors the functional way
every real system fails sometimes. the question isn't whether the errors happen, it's how clearly your code admits it. make errors visible, composable, and clean.
why errors are usually second-class citizens
in most code, a function's type signature lies to you. consider this:
type CheckAddressExists =
UnvalidatedAddress -> CheckedAddress
this says: "Give me an address, I'll give you a checked one." it says nothing about what happens when the address service times out, or the format is wrong, or the address simply doesn't exist. all of that is hidden, a surprise waiting to happen.
the function approach is to be honest in the type:
type CheckAddressExists =
UnvalidatedAddress -> Result<CheckedAddress, AddressValidationError>
now the signature is documentation. you know it can fail, and you know why.
three kinds of errors
not all errors deserve the same response. here's how to categorize them:

domain errors need real attention, discuss them with domain experts and model them as types. panics should be caught at the very top of your application and logged, don't try to recover. infrastructure errors can often be treated just like domain errors, which forces you to think about what happens when the database is down.
the problem: errors make code ugly
when you properly check for errors at every step, straightforward code turns into this:
let validateOrder unvalidatedOrder =
let orderIdResult = ... // create order id (or return Error)
if orderIdResult is Error then return
let customerInfoResult = ... // create customer (or return Error)
if customerInfoResult is Error then return
try
let shippingAddressResult = ... // validate address (or return Error)
if shippingAddressResult is Error then return
// ...
with
| TimeoutException -> Error "service timed out"
| AuthenticationException -> Error "bad credentials"
two-thirds of this code is now plumbing. the actual logic is buried. there must be a better way.
the big idea: railroad-oriented programming
think of every function as a piece of railway track. a normal function is a single straight track, data goes in, data comes out.
a function that can fail is a track that splits in two directions: success goes forward, failure gets shunted off onto a separate track.
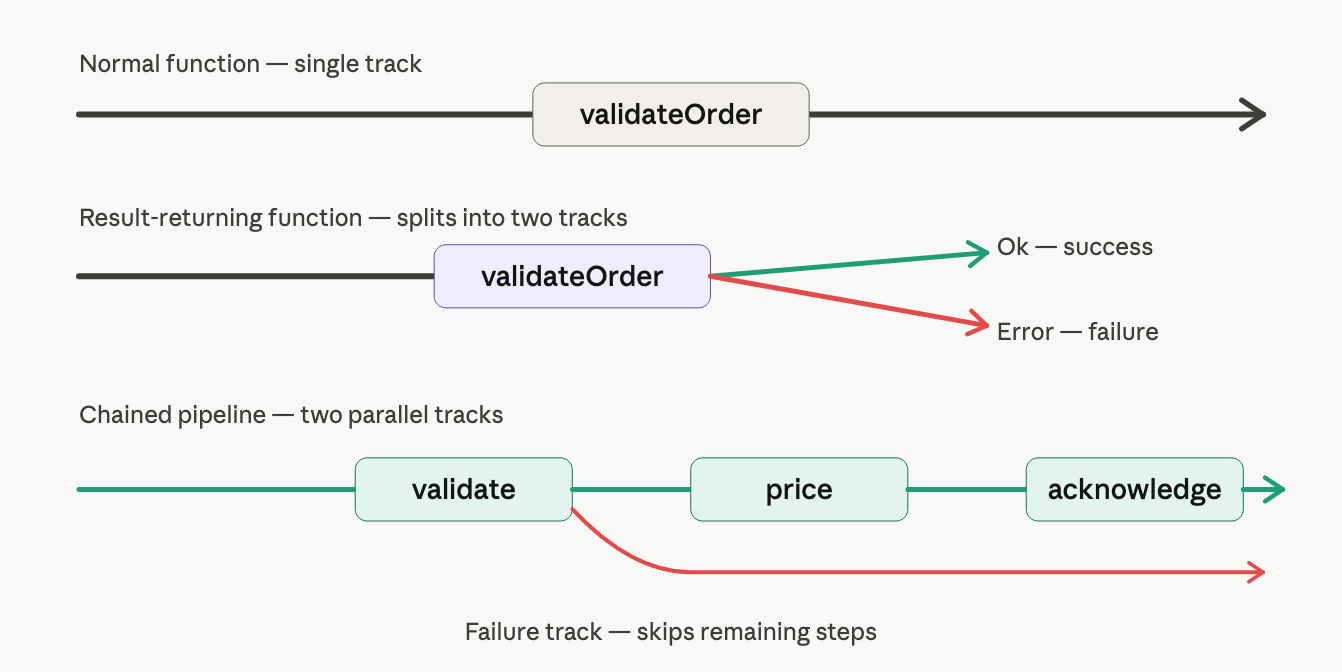
once you're on the failure track, you stay there. every subsequent step is bypassed automatically. you never need to write if error then return again.
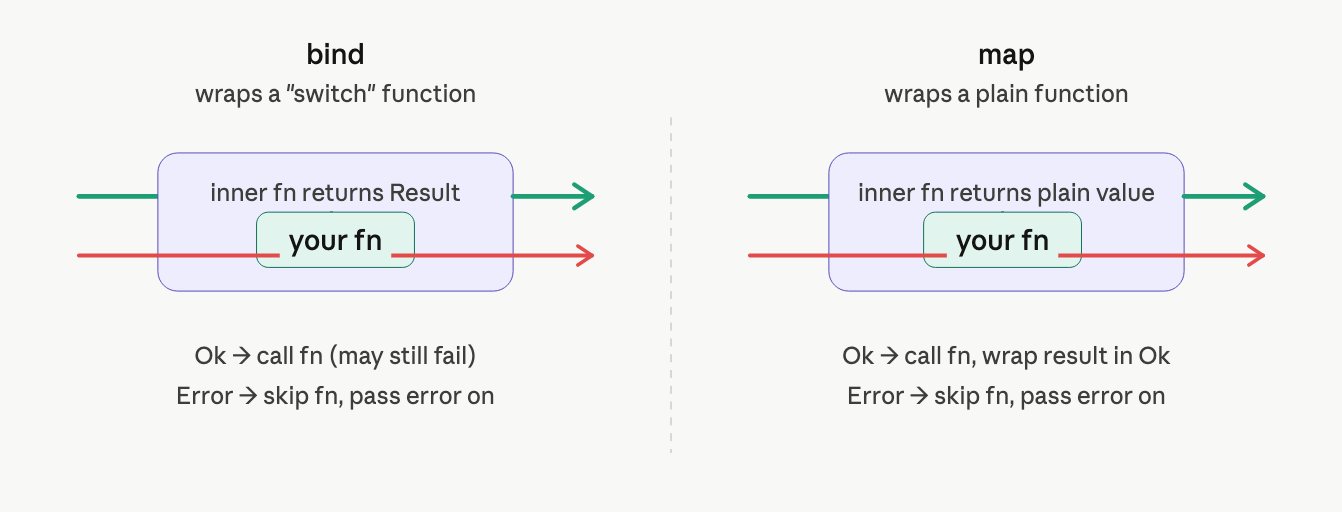
the two adapter functions: bind and map
the problem is mechanical: a function that takes a plain value can't directly receive a Result. you need an adapter that knows how to unwrap it first.
use bind for functions that can themselves fail
bind takes a switch function (one that returns a Result) and converts it into a two-track function:
let bind switchFn twoTrackInput =
match twoTrackInput with
| Ok success -> switchFn success // unwrap and call the function
| Error failure -> Error failure // pass the error straight through
in plain English: "if we're still on the success track, call the function. if we've already failed, skip it."
use map for functions that always success
map is for functions that can't fail, they just transform data. we still need to slot them into the two-track pipeline:
let map f aResult =
match aResult with
| Ok success -> Ok (f success) // call function, rewrap in Ok
| Error failure -> Error failure // pass error through
here's how the two adapter types behave differently:
the error type must be uniform across the pipeline
here's a subtle constraint: the success type can change at each step (an order goes from unvalidated -> validated -> priced), but the error type must stay the same all the way through.
if validateOrder returns ValidationError and priceOrder returns PricingError, they can't be chained, the types doesn't match.
the fix is to define a single combined error type for the whole pipeline, and use mapError to convert each function's specific error into it:
type PlaceOrderError =
| Validation of ValidationError
| Pricing of PricingError
// Lift each function's error to the shared type
let validateOrderAdapted input =
input
|> validateOrder
|> Result.mapError PlaceOrderError.Validation
let priceOrderAdapted input =
input
|> priceOrder
|> Result.mapError PlaceOrderError.Pricing
now they can be chained cleanly:
let placeOrder unvalidatedOrder =
unvalidatedOrder
|> validateOrderAdapted // bind not needed — it's first
|> Result.bind priceOrderAdapted
|> Result.map acknowledgeOrder
|> Result.map createEvents
handling special function shapes
not every function you encounter will be a neat switch function. two common awkward cases:
exception-throwing code (e.g. external libraries)
wrap it in an adapter that catches only the exceptions relevant to your domain:
let serviceExceptionAdapter serviceInfo serviceFn x =
try
Ok (serviceFn x)
with
| :? TimeoutException as ex ->
Error { Service = serviceInfo; Exception = ex }
| :? AuthorizationException as ex ->
Error { Service = serviceInfo; Exception = ex }
notice: we don't catch everything, only the exceptions that are meaningful to the domain. the rest bubble up to the top-level panic handler.
dead-end functions (nothing returned, e.g. logging)
a logger takes data but returns nothing (unit). we can't put nothing on a two-track pipeline. the trick is tee, call the function for its side effect, then pass the original value through unchanged:
let tee f x =
f x // run the side-effect
x // return the original input
let adaptDeadEnd f =
Result.map (tee f)
computation expressions, making it look clean
when the pipeline gets complicated (conditionals, loops, nested Results), even bind and map get verbose. F# has a built-in solution: computation expressions.
you define a result block, and inside it you use let! instead of let. the ! secretly calls bind for you, it unwraps the Result and gives you the plain value:
let placeOrder unvalidatedOrder =
result {
let! validatedOrder =
validateOrder unvalidatedOrder
|> Result.mapError PlaceOrderError.Validation
let! pricedOrder =
priceOrder validatedOrder
|> Result.mapError PlaceOrderError.Pricing
let acknowledgmentOption = acknowledgeOrder pricedOrder
let events = createEvents pricedOrder acknowledgmentOption
return events
}
compare this to the ugly if-chain from the start of the chapter. the error handling is entirely hidden. if any step returns Error, the whole block short-circuits, but you don't see a single if or try/catch.
the result builder itself is tiny to implement:
type ResultBuilder() =
member this.Return(x) = Ok x
member this.Bind(x, f) = Result.bind f x
let result = ResultBuilder()
working with lists of results
one tricky case: validating a list of order lines. if you use List.map with a function that returns Result, you get a list of Results, but you actually want a Result of list:
List<Result<Line, Error>> ← what you get
Result<List<Line>, Error> ← what you need
the solution is Result.sequence, it walks the list and either returns all the successes together, or the first error:
let sequence aListOfResults =
let initialValue = Ok []
List.foldBack prepend aListOfResults initialValue
usage is simple:
let! lines =
unvalidatedOrder.Lines
|> List.map (toValidatedOrderLine checkProductCodeExists)
|> Result.sequence // collapses List<Result> into Result<List>
adding async into the mix
in production, most of these steps are asynchronous, database calls, service calls, etc. the good news: the same pattern applies. you swap result {} for asyncResult {}, and every let! now handles both async and error unwrapping at once:
let placeOrder unvalidatedOrder =
asyncResult {
let! validatedOrder =
validateOrder checkProductExists checkAddressExists unvalidatedOrder
|> AsyncResult.mapError PlaceOrderError.Validation
let! pricedOrder =
priceOrder getProductPrice validatedOrder
|> AsyncResult.ofResult
|> AsyncResult.mapError PlaceOrderError.Pricing
return createEvents pricedOrder (acknowledgeOrder pricedOrder)
}
the top-level placeOrder is still clean, readable, and honest about what can go wrong.
the vocabulary
| term | what it means |
|---|---|
| Result | a type with two states: Ok value or Error reason |
| switch function | a function that returns a Result — it might succeed or fail |
| bind | adapts a switch function to fit in the two-track pipeline |
| map | adapts a always-succeeding function to fit the two-track pipeline |
| mapError | transforms the error type (to unify them across the pipeline) |
| monad | the formal name for the Result + bind + return pattern |
| applicative | like a monad, but runs things in parallel and collects all errors |
| computation expression | F# syntax sugar that hides bind calls behind let! |
the payoff
compare where we started, ugly cascading if-checks, to where we ended up:
- every function's type signature honestly documents what can go wrong
- the happy-path logic reads as a clean linear flow
- errors are handled automatically by the pipeline, no
try/catchpollution - the compiler enforces that you've handled every error case (add a new one, and the code won't compile until you've dealt with it)
this is the functional approach to errors: make them explicit, give them first-class status, and let the type system do the bookkeeping.
serialization
two worlds, two different languages
your domain model is rich and precise. you have types like OrderQty that can only hold valid quantities, ProductCode that must follow a specific format, and complex nested structures that enforce business rules.
but the outside world, HTTP requests, message queues, databases, understands none of that. it speaks JSON, XML, bytes.
serialization is the act of translating between these two worlds.
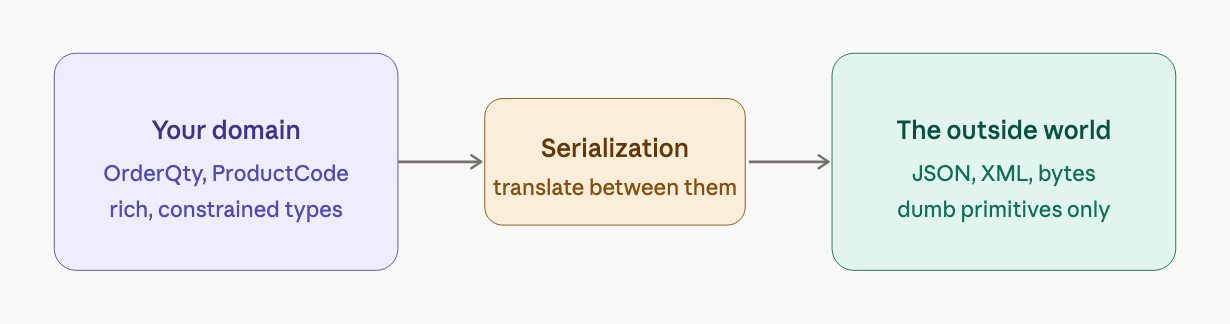
never serialize your domain types directly
why not? because domain types are designed for correctness, not simplicity. a JSON library faced with OrderQty of int wrapped in a discriminated union doesn't know what to do with it.
the solution is to create a Data Transfer Object (DTO) which is a plain, flat version of your type using only primitives that any serializer understands.
the DTO pattern
a DTO is a dumb twin of your domain type. same fields, but striped of all constraints.
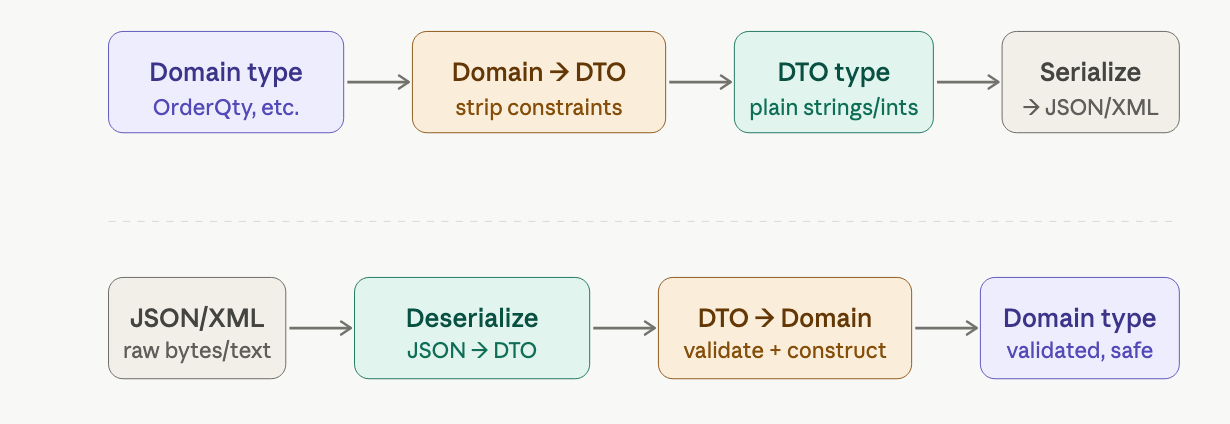
deserialization into a DTO should always succeed (unless the bytes are literally corrupt). all domain-specific validation happens in the DTO-to-domain step, where you have full control over error handling.
a concrete example: serializing a Person
step 1 - define your domain type
type String50 = String50 of string // max 50 chars, not empty
type Birthdate = Birthdate of DateTime // must be after 1900
type Person = {
First : String50
Last : String50
Birthdate : Birthdate
}
step 2 - define the DTO
module Dto =
type Person = {
First : string // just a string — no constraint
Last : string
Birthdate : DateTime
}
step 3 - write fromDomain and toDomain converters
fromDomain always succeeds, nothing can go wrong
let fromDomain (person: Domain.Person) : Dto.Person =
{ First = person.First |> String50.value
Last = person.Last |> String50.value
Birthdate = person.Birthdate |> Birthdate.value }
toDomain can fail, external data are unpredictable
let toDomain (dto: Dto.Person) : Result<Domain.Person, string> =
result {
let! first = dto.First |> String50.create "First"
let! last = dto.Last |> String50.create "Last"
let! birthdate = dto.Birthdate |> Birthdate.create
return { First = first; Last = last; Birthdate = birthdate }
}
plugging serialization into a pipeline
serialization is just another function in your pipeline, one at each end:

in code, this is a simple pipe chain:
let workflowWithSerialization jsonString =
jsonString
|> deserializeInputDto // JSON → DTO
|> inputDtoToDomain // DTO → domain object
|> workflow // the core domain logic
|> outputDtoFromDomain // domain object → DTO
|> serializeOutputDto // DTO → JSON
the infrastructure only ever sees JSON strings. the domain model is fully insulated.
how to map each F# type to a DTO
different F# types need different DTO treatments:
single-case union -> string
option type -> nullable int
record -> record with each field converted
list/set/seq -> array
enum-style union -> enum (integer) or strings
choice union -> record with a tag field + one field
handling choice types (discriminated unions with data)
this is the trickiest case. say you have:
type Example =
| A // empty
| B of int
| C of string list
| D of Name
the DTO uses a Tag string to say which case is active, plus one nullable field per case:
type ExampleDto = {
Tag : string // "A", "B", "C", or "D"
BData : Nullable<int> // only populated if Tag = "B"
CData : string[] // only populated if Tag = "C"
DData : NameDto // only populated if Tag = "D"
}
when serializing, you fill in only the relevant field and set the rest to null. when deserializing, you match on Tag and, crucially, check that the corresponding data field is not null before using it.
handling errors in the deserialization pipeline
two things can go wrong when deserializing:
- the JSON itself is malformed (corrupted bytes, syntax error)
- the data is valid JSON, but fails domain validation (e.g. an empty
Firstname)
these are different errors, so model them differently:
type DtoError =
| ValidationError of string
| DeserializationException of exn
let jsonToDomain jsonString : Result<Domain.Person, DtoError> =
result {
let! dto =
jsonString
|> Json.deserialize
|> Result.mapError DeserializationException // wrap JSON errors
let! person =
dto
|> Dto.Person.toDomain
|> Result.mapError ValidationError // wrap validation errors
return person
}
wrapping the JSON library
third-party JSON libraries often throw exceptions. wrap them so they fit neatly into your Result-based pipeline:
module Json =
let serialize obj =
JsonConvert.SerializeObject obj // always succeeds
let deserialize<'a> str =
try
JsonConvert.DeserializeObject<'a> str |> Ok
with
| ex -> Error ex // exceptions become Error values
DTOs are a contract - threat them carefully
the events your workflow emits and the commands it receives form an implicit contract with every other bounded context that communicates with yours.
if you change your DTO type, rename a field, remove a case, you silently break every consumer. so:
- never let a library auto-generate the serialization format without your control
- consider versioning DTOs explicitly when the domain evolves (adding a
v2DTO type alongside the originalv1) - keep DTO changes rare and deliberate
persistence
persistence or database think in rows and table and it almost always creates friction as they are not in the rich domain types you have carefully designed.
principle 1 - keep i/o at the edges

a function that reads from or writes to the outside world cannot be "pure". pure functions are easy to reason about and test. so push all database calls to the outside of your workflow.
the pure core contains all your business rules. it takes data as inputs, makes decisions, and returns a result type describing what should happen next. it never touches a database directly.
the i/o edges load what the core needs before it runs, then act on whatever decision the core returns.
here's what the difference looks like in practice:
❌ Mixed (hard to test):
let payInvoice invoiceId payment =
let invoice = loadInvoiceFromDatabase(invoiceId) // I/O mixed in
invoice.ApplyPayment(payment)
if invoice.IsFullyPaid then
markAsFullyPaidInDb(invoiceId) // I/O mixed in
✅ Separated (pure core + I/O edges):
// Pure — no DB, no side effects, easy to unit test
let applyPayment unpaidInvoice payment : InvoicePaymentResult =
if isFullyPaid updatedInvoice then FullyPaid
else PartiallyPaid updatedInvoice
// Edge — handles all I/O, calls pure core
let payInvoice command =
let invoice = loadInvoiceFromDatabase command.InvoiceId // I/O
let result = applyPayment invoice command.Payment // pure
match result with
| FullyPaid -> markAsFullyPaidInDb command.InvoiceId
| PartiallyPaid inv -> updateInvoiceInDb inv
the edge function doesn't make any decisions itself, it just orchestrates. because of that, you don't really need to unit test it; an integration test covers it fine.
what about the repository pattern? in object-oriented DDD, the repository pattern wraps database access behind an interface. in functional DDD you don't need it. instead of one interface with dozens of methods, you define a specific function for each i/o operation you actually need, and inject only those. simpler, more maintainable.
when you need multiple i/o steps
sometimes one i/o-pure-i/o sandwich isn't enough. your workflow may need to load data, decide something, save, load more data, decide again, save again. that's fine, you just get a "layer case" instead.
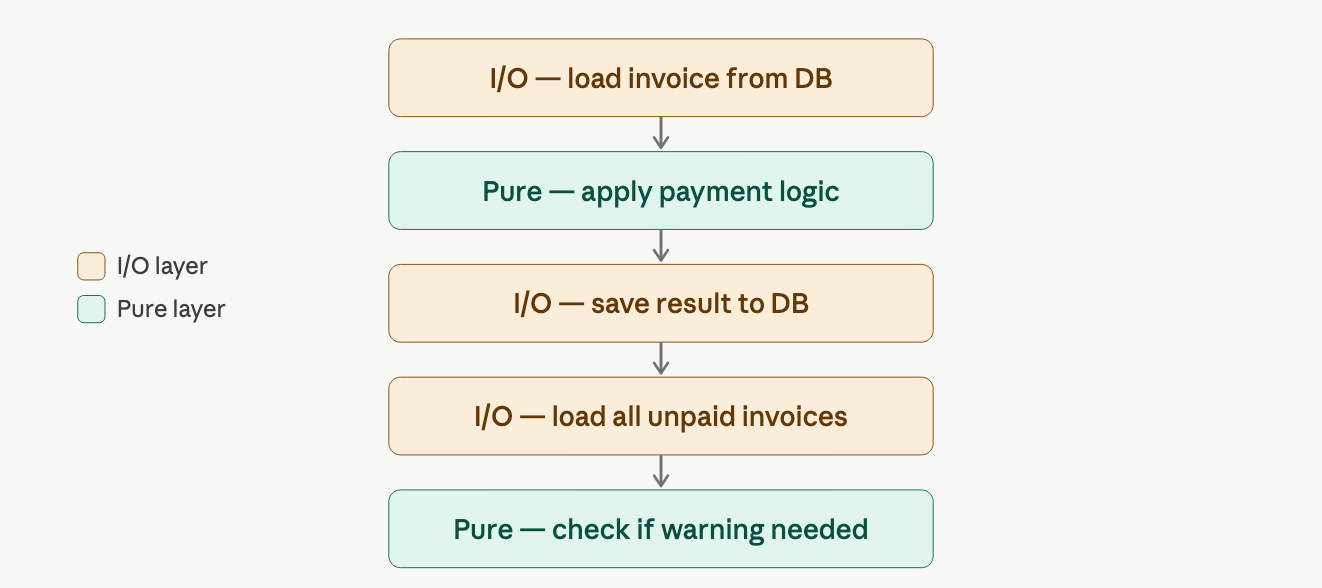
if this gets too complex, the advice is: break into smaller mini-workflows. each one stays a simple sandwich, and they chain together.
principle 2 - separate reads from writes (CQS)
command-query separation (CQS) is a simple but powerful idea:
a function that returns data should not change anything. a function that changes data should not return anything meaningful.
in other words: asking a question should not change the answer.
applied to databases, your four basic operations split cleanly:
| Operation | Changes DB? | Returns data? | Type |
|---|---|---|---|
| Insert | ✅ | ❌ | Command |
| Update | ✅ | ❌ | Command |
| Delete | ✅ | ❌ | Command |
| Read | ❌ | ✅ | Query |
in F# type signatures this looks like:
type InsertData = Data -> DbResult<Unit> // Command — returns nothing useful
type ReadData = Query -> DbResult<Data> // Query — returns data, changes nothing
type UpdateData = Data -> DbResult<Unit> // Command
type DeleteData = Key -> DbResult<Unit> // Command
DbResult wraps AsyncResult to handle both async execution and possible errors gracefully.
taking CQS further - CQRS
once you separate reads from writes, a natural next step is to model them with completely different types. this is called command-query responsibility segregation (CQRS).
why not reuse the same Customer type for both reads and writes?
- reads often return extra data - calculated fields, joined data from multiple tables - that you'd never write back.
- writes often emit fields - like auto-generated IDs - that reads always include.
- they evolve independently. you might add three new query types without changing the write model at all.
so instead of one Customer type doing double duty:
type SaveCustomer = WriteModel.Customer -> DbResult<Unit>
type LoadCustomer = CustomerId -> DbResult<ReadModel.Customer>
two different models, two different purposes, cleanly decoupled.
you can even push this to separate databases: one write store optimized for transactional updates, one read store optimized for queries (denormalized, heavily indexed). the trade-off is eventually consistency - the read store may lag slightly behind the write store.
principle 3 - bounded contexts own their data
each bounded context must own its own data storage. no other system can reach directly into another context's database. if it does, the two systems are coupled, even if their codebases are completely separate.
the implementation can vary:
- maximum isolation: each context has its own physical databases.
- practical middle ground: one physical database, but each context uses its own schema namespace, logically separate, operationally simpler.
what about reporting? a reporting system needs data from multiple contexts, but direct cross-context DB access breaks isolation. the solution is to treat reporting or business intelligence as its own bounded context. feed it data by having it subscribe to events emitted by other contexts, or use a traditional ETL pipeline to copy data across.
persisting to a document database (NoSQL)
this is the easy case. convert your domain object -> DTO -> JSON, then store it. load it back by reversing the process (serialization).
let savePersonDtoToBlob personDto =
let blobId = sprintf "Person%i" personDto.PersonId
let blob = container.GetBlockBlobReference(blobId)
let json = Json.serialize personDto
blob.UploadText(json)
that's it. document databases store your data largely as-is, so there's minimal friction with your domain types.
persisting to a relational database (SQL)
this is where things get interesting. relational databases only store primitive values (strings, ints, dates). your domain types need to be unwrapped before storing and revalidated after loading.
simple record types map cleanly to tables:
CREATE TABLE Customer (
CustomerId int NOT NULL,
Name NVARCHAR(50) NOT NULL,
Birthdate DATETIME NULL,
CONSTRAINT PK_Customer PRIMARY KEY (CustomerId)
)
choice types (discriminated unions) are trickier. two main approaches:
- everything in one table
CREATE TABLE ContactInfo (
ContactId int NOT NULL,
IsEmail bit NOT NULL, -- which case is active?
IsPhone bit NOT NULL,
EmailAddress NVARCHAR(100), -- NULL when IsPhone
PhoneNumber NVARCHAR(25), -- NULL when IsEmail
...
)
pros: simple to query. cons: nullable columns, weaker constraints.
- separate table per case (stricter)
a main table with the shared ID and flag, plus one child table per case, each with NOT NULL columns. more joints, but better data integrity.
for nested types, follow this rule of thumb: if the nested type is a DDD Entity (has its own identity), give it its own table with a foreign key. if it's a Value Object (no identity), inline its columns into the parent table.
reading from a relational database
the key insight: treat the database as an untrusted source of data. just like deserializing JSON from an external API, you validate what comes back.
using F#'s SQL type providers, your SQL query generates a matching record type at compile time. if the SQL is wrong, you get a compile error, not a runtime surprise.
the toDomain function validates and reconstructs your domain type:
let toDomain (dbRecord: ReadOneCustomer.Record) : Result<Customer, _> =
result {
let! customerId = dbRecord.CustomerId |> CustomerId.create
let! name = dbRecord.Name |> String50.create "Name"
let! birthdate = dbRecord.Birthdate |> Result.bindOption Birthdate.create
return { CustomerId = customerId; Name = name; Birthdate = birthdate }
}
yes, this is more code than an ORM would require. but ORMs can't validate that an email address is actually valid, or that an order quantity is positive. you are buying correctness at the cost of a little extra code, and it's mechanical, straightforward code at that.
writing to a relational database
the pattern mirrors reading: unwrap your domain types into primitives, then execute a SQL command.
let writeContact (conn: SqlConnection) (contact: Contact) =
let contactId = contact.ContactId |> ContactId.value
let isEmail, isPhone, emailAddress, phoneNumber =
match contact.Info with
| Email e -> true, false, EmailAddress.value e, null
| Phone p -> false, true, null, PhoneNumber.value p
use cmd = new InsertContact(conn)
cmd.Execute(contactId, isEmail, isPhone, emailAddress, phoneNumber)
transactions
when multiple things must be saved automatically (all-or-nothing), you have options:
same connection: wrap multiple calls in a BeginTransaction() / Commit() block.
cross-service: you generally can't have transactions across different services. instead, assume success and use compensating transactions to undo work if something fails later:
markAsFullyPaid connection invoiceId
let result = markPaymentCompleted connection paymentId
match result with
| Error _ -> unmarkAsFullyPaid connection invoiceId // compensate
| Ok _ -> ()
this matches how real-world businesses operate, accountants don't require a distributed transaction lock across every system to record a payment.